Intro to GraphGrid NLP
GraphGrid Natural Language Processing (NLP) provides a domain for graph-based data processing. This service uses text-to-graph data processing along with a variety of natural language processing features. By analyzing text, GraphGrid NLP can interpret and extract a text data structure and store it in a graph database. This extraction, along with several NLP features, forms a framework of tools for real-time text processing in several languages; as well as analysis capable of determining the evolution of articles/text data over time.
This tutorial will teach you how the basics of GraphGrid NLP for text-to-graph data processing.
NLP Basics: Tutorial Overview
- Add textual data to the graph (movie plots and summaries).
- Extract relevant information into the graph using data processing.
- Create a document policy to unravel data used by NLP features.
- Summarize a text.
- Find similar articles using similarity clustering.
- Set up Continuous Processing (CP).
GraphGrid's NLP models used in data processing:
- part_of_speech_tagging (PoS)
- named_entity_recognition (NER)
- coreference_resolution (CRR)
- sentiment_analysis_binary
- sentiment_analysis_categorical
- keyphrase_extraction (KE)
- relation_extraction (RE)
- translation
Click here more information regarding NLP tasks.
Add Textual Data to The Graph
Time to get hands on! Below is a link to a file that contains Geequel queries that will add several Article nodes to our graph.
These Article nodes contain movie summaries and information. Click on the link and copy and paste the contents from
that file into ONgDB.
Data Processing
Data processing extracts relevant information from text data by using trained NLP models. Each processed text node will have an
AnnotatedText node. The gathered information from processing is stored as a
graphical structure related to that article's AnnotatedText node.
See the photo below for an example of how data processing creates a web of data (using an article about Spider-Man was a total coincidence).
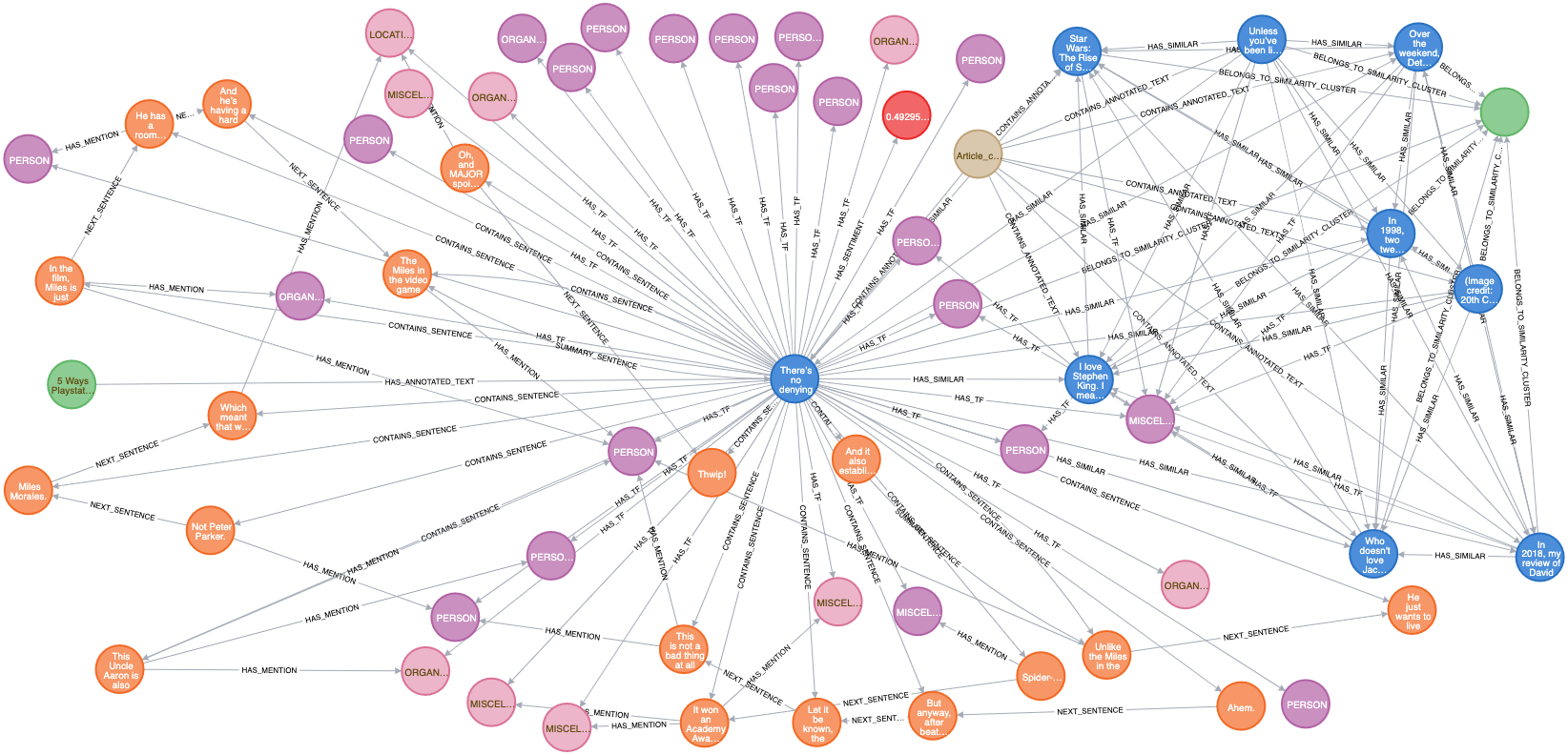
The green node showing "5 Ways Playstat..." is the original `Article` node (source) if you're interested in checking out the full text). The blue node in the center showing "There's no denying" is the `AnnotatedText` node for the original article. The other blue nodes are also AnnotatedText nodes that NLP has determined are
similar. You may notice relationships between them that say HAS_SIMILAR or BELONGS_TO_SIMILARITY_CLUSTER.
Here is a breakdown the other nodes:
- Pink- These are mention nodes. Mention nodes have NER values like "Person", "Location", or "Organization". For example, a mention node with an NER value of "Person" might hold information about "Spider-Man", and a "Location" might hold information about "Queens, New York City". Mention nodes can also have relationships called "HAS_TF". These relationships help determine how articles are similar.
- Orange- The orange nodes are sentence nodes. NLP picks apart each sentence and extracts the information it thinks is relevant based on the models it is trained on.
- Red- These are `AnnotatedTextSentiment` nodes. They give the sentiment score of the `AnnotatedText` node.
- Tan- The tan node is the `corpus` node. This node is connected to every article in the graph. Like a regular corpus, it is a collection of texts but in GraphGrid exists in a graph form. Think of the corpus like a folder that contains all the data processing information.
Data Processing Request
There are two API endpoints that can manually extract our text data, fullDataExtraction and partialDataExtraction.
fullDataExtraction is only to be used when there are no AnnotatedText nodes on the graph. If there are already annotated nodes
on the graph, running fullDataExtraction will cause NLP to process those article nodes again and create a duplicate AnnotatedText node. For the first pass with
fresh data, we can use fullDataExtraction.
If new data is added to the graph after the first pass of data processing, use the partialDataExtraction endpoint. partialDataExtraction will only process
the article nodes that do not have AnnotatedText nodes. NLP is also able to utilize a message broker for continuousProcessing which runs the data
processing automatically.
Since we have not run data processing yet, we can use fullDataExtraction. If we had already run data processing, we'd use the partialDataExtraction endpoint.
We will tell NLP to look for nodes with the label Article and process their content property.
NLP Data Processing takes a variable amount of time to process the text of each node. Data processing is performed over three phases:
- Phase 0 (or preprocessing)
- Concentrates on preprocessing the text, for example translating or cleaning it.
- Phase 1 (base data processing)
- Phase 1 concentrates on using BERT and CoreNLP as a backbone to extract information from the text, and writing that to the graph.
- Phase 2 (supplementary data processing)
- Concentrates on supplementing the base data processing, like tf-idf scores, document similarity, and article summarization.
/fullDataExtraction_bert/
curl --location --request POST "${API_BASE}/1.0/nlp/fullDataExtraction_bert" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}" \
--data-raw '{
"label": "Article",
"property": "content"
}'
To check data processing progress, run this Geequel query in ONgDB:
MATCH (a:Article)-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText) RETURN a, at
This query returns all Article nodes that have an AnnotatedText node. Once each of the nodes has an AnnotatedText node NLP is finished processing.
You can also check the NLP logs using this docker command in your terminal:
docker-compose logs -f nlp
This will bring up and follow the NLP container's logs so you can track its progress. The last step in the process is summarizing the text nodes. The process is
finished when you see SUMMARY_SENTENCE relationships appear in the logs.

Document Policy
The next step is to create a document policy. NLP uses a document policy to unravel the graph data to be used for NLP's features.
/saveDocumentPolicy/
For this data set, our document policy needs to be set like this:
curl --location --request POST "${API_BASE}/1.0/nlp/default/saveDocumentPolicy/gg-dev-document-policy" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}" \
--data-raw '{
"metadata": {
"displayName": "gg-dev-document-policy",
"createdAt": "2019-05-15T11:06:17+00:00",
"updatedAt": "2019-09-03T12:58:52+00:00"
},
"label": "Article",
"textProperty": "content",
"getDocumentCardCypher": "UNWIND $batchedDocumentGrns AS articleGrn MATCH (article:Article {grn: articleGrn})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText) WITH article, at MATCH (at)-[:HAS_SENTIMENT]->(ats:AnnotatedTextSentiment) OPTIONAL MATCH (at)-[r:SUMMARY_SENTENCE]->(s:Sentence) WITH article, at, ats, r, s ORDER BY r.order WITH article, at, ats, rTrim(reduce(acc = '\'''\'', n IN COLLECT(s)| acc + n.sentence + '\'' '\'')) AS summary WITH article, at, ats, replace(summary, '\''\"'\'', '\'''\'') AS summary WITH article, at, ats, replace(summary, '\''"'\'', '\'''\'') AS summary WITH article, at, ats, replace(summary, '\''"'\'', '\'''\'') AS processedSummary MATCH (at)-[:HAS_TF]->(m:Mention) WITH article, at, ats, m, processedSummary OPTIONAL MATCH (m)<-[:MENTION_REPRESENTATIVE]-(x:KnowledgeGraphEntity) WITH article, at, ats, x, m, processedSummary OPTIONAL MATCH (rssSource:RSSSource {name: article.source}) WITH article, at, ats, x, m, processedSummary, rssSource OPTIONAL MATCH (article)<-[:HAS_TRANSLATION]-(nativeArticle:Article) RETURN article.grn AS grn, processedSummary AS summary, article.content AS fullText, article.pubDate as publishDate, article.title AS title, article.source AS source, rssSource.score AS trustScore, article.link AS sourceUrl, ats.sentiment AS sentiment, COLLECT(DISTINCT m.value) AS tags, '\''en'\'' AS language, COLLECT(x.grn) AS knowledgeGraphEntities, nativeArticle.content AS translatedFullText, nativeArticle.title AS translatedTitle, nativeArticle.grn AS nativeTextGrn",
"documentCardBatchVariable": "batchedDocumentGrns"
}'
Summarize a Text
Now that we have a document policy, we can use features of NLP like similarity and summarization. First, let's
summarize a text using the AnnotatedText node's data and our document policy.
For this request we'll need the grn of the Article node we want to summarize, and its Corpus node. To find
these, run these two queries in ONgDB:
- Return the grn of the
Articlenode with the title property "The Shawshank Redemption".
MATCH (n:Article {title: "The Shawshank Redemption"}) RETURN n.grn
- Return the grn of the
Corpusnode.
MATCH (n:Corpus) RETURN n.grn
/summarizeText/
This request will summarize the plot of "The Shawshank Redemption" [SPOILER ALERT].
The Corpus and Article grns in this request are different from your own. Make sure to replace these values!
curl --location --request POST "${API_BASE}/1.0/nlp/summarizeText/grn:gg:corpus:Wep89P6l7ijE2PS7JvWLYuh57I6Osi7hbK581hirPXuu/Article/grn:gg:article:1WS2qGstR7tgrtULcbHE8STtrQFvb2hcBjwkmWBt9BBz/5" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}"
Response/Results
{
"grn:gg:sentence:I9aU4hyAZ2EEaoopSNVtd6bo1QOgrV96eS7bcW4ohhBv": {
"text": "When Andy gets out of the infirmary, he finds a bunch of rocks for him to sculpt and a giant poster of Rita Hayworth in his cell; presents from Red and his friends.",
"order": 4
},
"grn:gg:sentence:vVBndacazyQ32OuaDXBVT8Leg09X9ZmTCjduJLX3eEuS": {
"text": "Red asks a few questions about his intentions which Andy laughs off. ",
"order": 3
},
"grn:gg:sentence:1c9llQgUSt2lRLx9J7Mh3ft0Ebi7b43w3AhwxqVtkjqQ": {
"text": "Red remarks:'These walls are funny. ",
"order": 1
},
"grn:gg:sentence:YRuR5gXy6i9FiQHYRoVFBgcSbQoB8hpnsFJRJH7cnHxi": {
"text": "When he gets out, he tells his friends that the stretch was the 'easiest time' he ever did in the hole because he spent it with Mozart's Figaro stuck in his head for comfort. ",
"order": 2
},
"grn:gg:sentence:lwucBHd2VM1ryjhjCwPxVjQH0alCrxHiXVuKPzLTApq0": {
"text": "Andy responds by turning up the volume. ",
"order": 0
}
}
Recap: Steps for Summarization
To summarize a text we :
- processed text nodes using the
fullDataExtraction_bertendpoint. - created a document policy to unravel data to be used by NLP module features with the
saveDocumentPolicyendpoint. - retrieved the grn of the
ArticleandCorpusnodes required to use thesummarizeTextendpoint. - ran
summarizeTextto summarize theArticlenode specified in the request parameters.
Similarity Clustering
Document similarities are scored based on a Term Frequency-Inverse Document Frequency (TF-IDF) method. Each document gets embedded in a corpus
based on their TF-IDF vectors. From there, the NLP module is able to calculate how similar two documents are. Term-frequency is calculated once per document and
stored on the graph in HAS_TF relationships, while inverse-document frequency is calculated as needed.
For example, see this image from the graph of the movie article nodes for "Shawshank Redemption" and "The Green Mile":
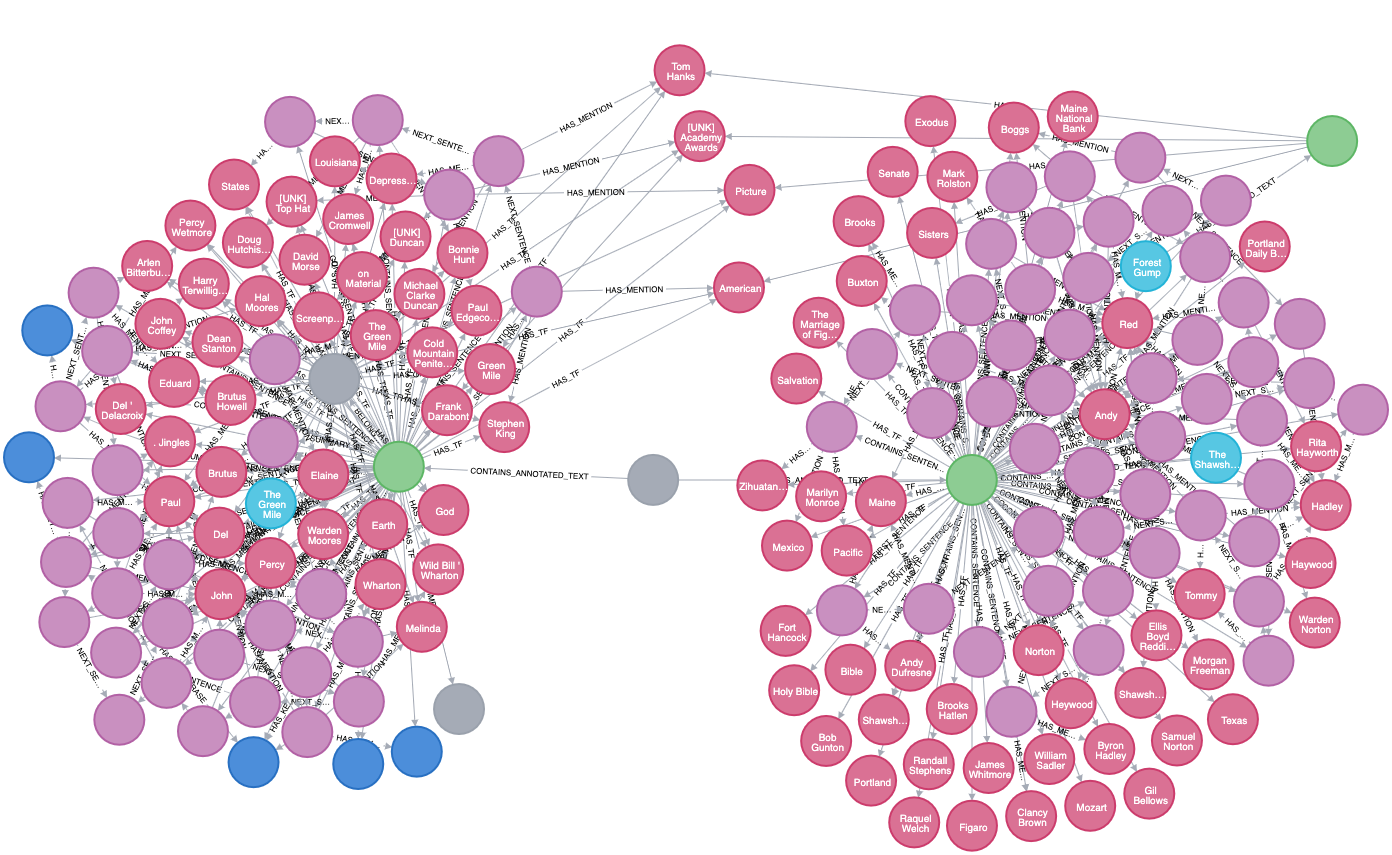
You can see the words they have in common based on their similarity scores and their HAS_TF relationships.
To put NLP into action ourselves, we can find similar movies based on the plot summaries and basic information provided in our article node. Let's try this on "Star Wars: The Rise of Skywalker"
Get Similar Documents
For this request we'll need the grn of the Article node we want to find similar documents for, and the corpus node. To find these, run these two queries in ONgDB:
- Return the grn of the
Articlenode with the title property "Star Wars: The Rise of Skywalker".
MATCH (n:Article {title: "Star Wars: The Rise of Skywalker"}) RETURN n.grn
- Return the grn of the
Corpusnode.
MATCH (n:Corpus) RETURN n.grn
/getSimilarDocumentCards/
The Corpus and Article grns in this request are different from your own. Make sure to replace these values!
curl --location --request GET "${API_BASE}/1.0/nlp/default/getSimilarDocumentCards/gg-dev-document-policy/grn:gg:corpus:Wep89P6l7ijE2PS7JvWLYuh57I6Osi7hbK581hirPXuu/grn:gg:article:sF4qUb9RZyNKuDxbQ8QBHzc0dbasyyHEbcVvlsv4EX5I" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}"
Response/Results
[
{
"grn": "grn:gg:article:UA5MfKvfMjpklX6hFyXQUWUQoSSg14pfx29MFjmj8BEW",
"publishDate": null,
"language": "en",
"imageUrl": null,
"title": "Star Wars: A New Hope",
"summary": "Before she is captured, Leia hides the plans in the memory system of astromech droid R2-D2, who flees in an escape pod to the nearby desert planet Tatooine alongside his companion, protocol droid C-3PO.\n It is the first installment of the original Star Wars trilogy, the first of the franchise to be produced, and the fourth episode of the 'Skywalker saga'.\n In 2004, its soundtrack was added to the U.S. It grossed a total of $775 million (over $550 million during its initial run), surpassing Jaws (1975) to become the highest-grossing film at the time until the release of E.T. the Extra-Terrestrial (1982). Library of Congress for preservation in the National Film Registry for being 'culturally, historically, or aesthetically significant'.[5][6] At the time, it was the most recent film in the registry and the only one chosen from the 1970s.",
"fullText": "Star Wars (retroactively titled Star Wars: Episode IV - A New Hope) is a 1977 American epic space-opera film written and directed by George Lucas, produced by Lucasfilm and distributed by 20th Century Fox. It stars Mark Hamill, Harrison Ford, Carrie Fisher, Peter Cushing, Alec Guinness, David Prowse, James Earl Jones, Anthony Daniels, Kenny Baker and Peter Mayhew. It is the first installment of the original Star Wars trilogy, the first of the franchise to be produced, and the fourth episode of the 'Skywalker saga'.\nLucas had the idea for a science-fiction film in the vein of Flash Gordon around the time he completed his first film, THX 1138 (1971) and began working on a treatment after the release of American Graffiti (1973). Star Wars takes place 'a long time ago', in a fictional universe inhabited by both humans and various alien species; most of the known galaxy is ruled by the tyrannical Galactic Empire, which is only opposed by the Rebel Alliance, a group of freedom fighters. The narrative of the film focuses on the hero journey of Luke Skywalker (Hamill), an everyman who becomes caught in the galactic conflict between the Empire and the Rebellion after coming into possession of two droids, R2-D2 (Baker) and C-3PO (Daniels), who are carrying the schematics of the Empire's ultimate weapon, the Death Star. While attempting to deliver the droids to the Rebellion, Luke is joined by wizened Jedi Master Obi-Wan Kenobi (Guinness), who teaches him about the metaphysical power known as 'the Force', cynical smuggler Han Solo (Ford), his Wookiee companion Chewbacca (Mayhew), and Rebellion leader Princess Leia (Fisher). Meanwhile, Imperial officers Darth Vader (Prowse, voiced by Jones), a Sith Lord, and Grand Moff Tarkin (Cushing), the commander of the Death Star, seek to retrieve the stolen schematics and locate the Rebellion's secret base.\nAfter a turbulent production, Star Wars was released in a limited number of theaters in the United States on May 25, 1977, and quickly became a blockbuster hit, leading to it being expanded to a much wider release. The film opened to critical acclaim, most notably for its groundbreaking visual effects. It grossed a total of $775 million (over $550 million during its initial run), surpassing Jaws (1975) to become the highest-grossing film at the time until the release of E.T. the Extra-Terrestrial (1982). When adjusted for inflation, Star Wars is the second-highest-grossing film in North America (behind Gone with the Wind) and the fourth-highest-grossing film in the world. It received ten Oscar nominations (including Best Picture), winning seven. In 1989, it became one of the first 25 films that was selected by the U.S. Library of Congress for preservation in the National Film Registry for being 'culturally, historically, or aesthetically significant'.[5][6] At the time, it was the most recent film in the registry and the only one chosen from the 1970s. In 2004, its soundtrack was added to the U.S. National Recording Registry, and was additionally listed by the American Film Institute as the best movie score of all time a year later. Today, it is widely regarded by many in the motion picture industry as one of the greatest and most important films in film history.\nThe film has been reissued multiple times with Lucas's support-most significantly with its 20th-anniversary theatrical 'Special Edition'-incorporating many changes including modified computer-generated effects, altered dialogue, re-edited shots, remixed soundtracks and added scenes. The film became a pop-cultural phenomenon and launched an industry of tie-in products, including novels, comics, video games, amusement park attractions, and merchandise including toys, games, clothing and many other spin-off works. The film's success led to two critically and commercially successful sequels, The Empire Strikes Back (1980) and Return of the Jedi (1983), and later to a prequel trilogy, a sequel trilogy, two anthology films and various spin-off TV series.\nAmid a galactic civil war, Rebel Alliance spies have stolen plans to the Galactic Empire's Death Star, a massive space station capable of destroying entire planets. Imperial Senator Princess Leia Organa of Alderaan, secretly one of the Rebellion's leaders, has obtained its schematics, but her starship is intercepted by an Imperial Star Destroyer under the command of the ruthless Darth Vader. Before she is captured, Leia hides the plans in the memory system of astromech droid R2-D2, who flees in an escape pod to the nearby desert planet Tatooine alongside his companion, protocol droid C-3PO.\nThe droids are captured by Jawa traders, who sell them to moisture farmers Owen and Beru Lars and their nephew Luke Skywalker. While Luke is cleaning R2-D2, he discovers a holographic recording of Leia requesting help from an Obi-Wan Kenobi. Later, after Luke finds R2-D2 missing, he is attacked by scavenging Sand People while searching for him, but is rescued by elderly hermit 'Old Ben' Kenobi, an acquaintance of Luke's, who reveals that 'Obi-Wan' is his true name. Obi-Wan tells Luke of his days as one of the Jedi Knights, the former peacekeepers of the Galactic Republic who drew mystical abilities from a metaphysical energy field known as 'the Force', but were ultimately hunted to near-extinction by the Empire. Luke learns that his father fought alongside Obi-Wan as a Jedi Knight during the Clone Wars until Vader, Obi-Wan's former pupil, turned to the dark side of the Force and murdered him. Obi-Wan gives Luke his father's old lightsaber, the signature weapon of Jedi Knights.\nR2-D2 plays Leia's full message, in which she begs Obi-Wan to take the Death Star plans to her home planet of Alderaan and give them to her father, a fellow veteran, for analysis. Although Luke initially declines Obi-Wan's offer to accompany him to Alderaan and learn the ways of the Force, he is left with no choice after discovering that Imperial stormtroopers have killed his aunt and uncle and destroyed their farm in their search for the droids. Traveling to a cantina in Mos Eisley to search for transport, Luke and Obi-Wan hire Han Solo, a smuggler with a price on his head due to his debt to local mobster Jabba the Hutt. Pursued by stormtroopers, Obi-Wan, Luke, R2-D2 and C-3PO flee Tatooine with Han and his Wookiee co-pilot Chewbacca on their ship the Millennium Falcon.\nBefore the Falcon can reach Alderaan, Death Star commander Grand Moff Tarkin destroys the planet in a show of force after interrogating Leia for the location of the Rebel Alliance's base. Upon arrival, the Falcon is captured by the Death Star's tractor beam, but the group manages to evade capture by hiding in the ship's smuggling compartments. As Obi-Wan leaves to disable the tractor beam, Luke persuades Han and Chewbacca to help him rescue Leia after discovering that she is scheduled to be executed. After disabling the tractor beam, Obi-Wan sacrifices himself in a lightsaber duel against Vader, allowing the rest of the group to escape the Death Star with Leia. Using a tracking device, the Empire tracks the Falcon to the hidden Rebel base on Yavin IV.\nThe schematics reveal a hidden weakness in the Death Star's thermal exhaust port, which could allow the Rebels to trigger a chain reaction in its main reactor with a precise proton torpedo strike. While Han abandons the Rebels after collecting his reward for rescuing Leia, Luke joins their X-wing starfighter squadron in a desperate attack against the approaching Death Star. In the ensuing battle, the Rebels suffer heavy losses as Vader leads a squadron of TIE fighters against them. Han and Chewbacca unexpectedly return to aid them in the Falcon, and knock Vader's ship off course before he can shoot down Luke. Guided by the disembodied voice of Obi-Wan's spirit, Luke uses the Force to aim his torpedoes into the exhaust port, destroying the Death Star moments before it fires on the Rebel base. In a triumphant ceremony at the base, Leia awards Luke and Han medals for their heroism.\n",
"source": "IMDb",
"sourceUrl": "https://www.imdb.com/title/tt0974015/?ref_=fn_al_tt_1",
"sentiment": 0.5555555555555556,
"trustScore": null,
"tags": [
"Wookiee",
"Alec Guinness",
"Galactic Empire",
"Old Ben ' Kenobi",
"Return of the Jedi [UNK]",
"Lucasfilm",
"Hutt",
"America",
"Force",
"Millennium Falcon",
"Fox",
"Fisher",
"Kenny Baker",
"[UNK] Rebel Alliance",
"Leia",
"[UNK] Galactic Empire",
"Tatooine",
"Imperial [UNK] Star Destroyer [UNK]",
"Alderaan",
"Empire",
"American",
"Wan",
"Luke",
"Clone",
"Wan Kenobi",
"Falcon [UNK]",
"Obi - Wan",
"Jedi Knights",
"Beru Lars [UNK]",
"Flash Gordon",
"Library",
"James Earl Jones",
"Rebel Alliance",
"Star Wars [UNK]",
"Death Star",
"Peter Cushing",
"Mayhew",
"Chewbacca",
"Picture",
"Gone with the Wind",
"Lucas",
"Rebels",
"Obi",
"Rebel",
"Princess Leia",
"U . S . [UNK]",
"droids",
"Mark Hamill",
"[UNK] Death Star",
"New Hope",
"Anthony Daniels",
"Guinness",
"Han",
"Film",
"Luke Skywalker",
"Rebellion",
"Ford",
"Skywalker",
"20th Century",
"Baker",
"National Film Registry",
"Owen [UNK]",
"Recording Registry",
"Carrie Fisher",
"Wars [UNK]",
"Strikes",
"[UNK] E . T .",
"David Prowse",
"United States",
"Mos Eisley",
"[UNK] Alderaan",
"Hamill",
"Jones",
"Moff Tarkin",
"Extra",
"Peter Mayhew",
"1977 American [UNK]",
"American Graffiti [UNK]",
"Jawa [UNK]",
"Imperial [UNK]",
"Oscar [UNK]",
"Wars",
"Cushing",
"Star Wars : Episode",
"Back",
"Leia Organa",
". S",
"Daniels",
"Harrison Ford",
"Jaws [UNK]",
"Knights",
"Galactic Republic",
"Prowse",
"Institute",
"Jabba",
"George",
"Falcon",
"galactic",
"THX 1138 [UNK]",
"Darth Vader",
"Han Solo",
"Jedi",
"Vader",
"Sith Lord"
],
"knowledgeGraphEntities": [
"grn:gg:knowledgegraphentity:Frv5Zw15IpQBWR7F6E9DLsn8k5aLoMgv1362t7ZbKU3r",
"grn:gg:knowledgegraphentity:RyS0OsSGqVuDsgPV9x2Zo6t6QGE1EwW78hhzCCZWhIqm",
"grn:gg:knowledgegraphentity:gCBH1b7QZXOQZazWUGhqEshIavLy49sxqiHOqEXTnNG8",
"grn:gg:knowledgegraphentity:w1tVvfPkNRDVZY3Ddpo6HhBLfKBBt6a00GHPalN2hyIP",
"grn:gg:knowledgegraphentity:MkMy6ZgHDr1jgDX372qA8UcEGW51iFl8E8FmfLRkaZX6",
...
],
"translatedFullText": null,
"translatedTitle": null,
"nativeTextGrn": null
}
]
The get similar documents requests gives us a result of "Star Wars: A New Hope", along with the tags that NLP used to create TF relationships to find similarity. This is just a small example for practice, but it shows the basic capibility of NLP similarity scoring.
The graph shows the similarty cluster between these two movies and their AnnotatedText node properties which make them similar.
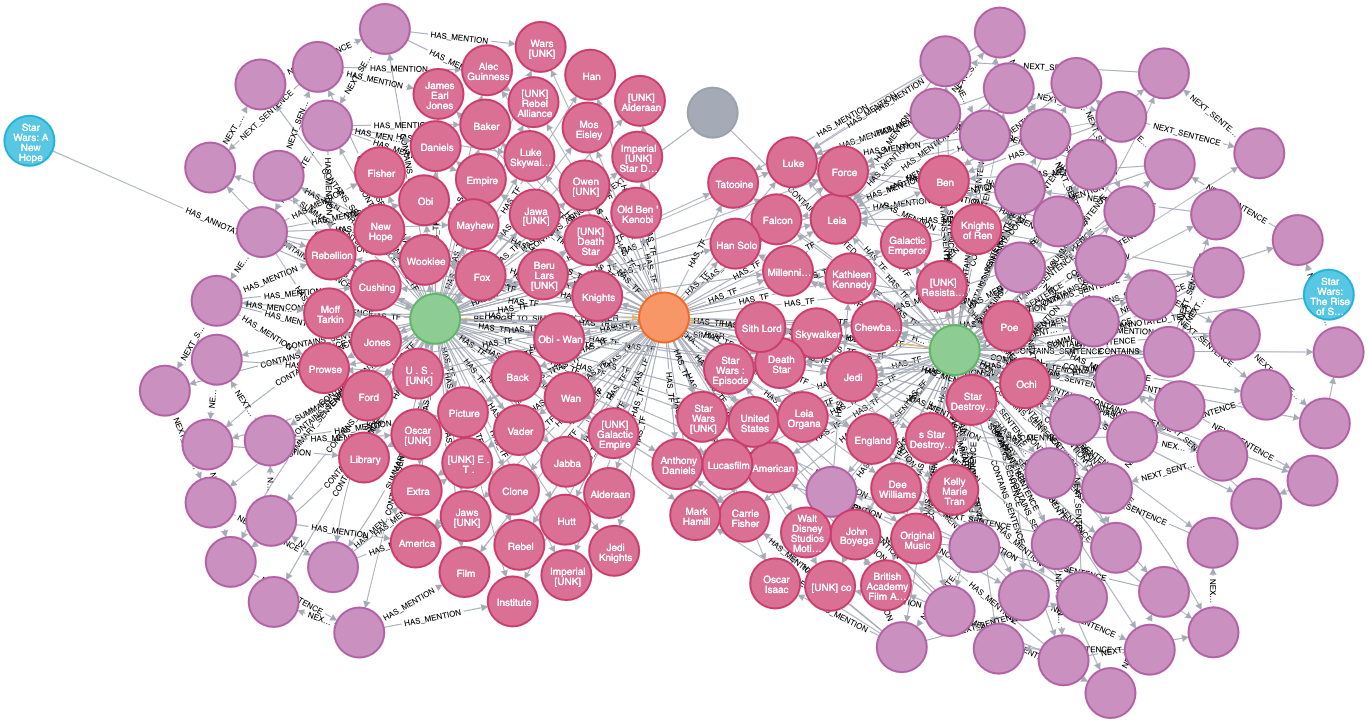
Recap: Steps for Similarity
To get similarity working we:
- processed text nodes using the
fullDataExtraction_bertendpoint. - created a document policy to unravel data to be used by NLP module features with the
saveDocumentPolicyendpoint. - retrieved the grn of the
ArticleandCorpusnodes required to use thegetSimilarDocumentCardsendpoint. - ran
getSimilarDocumentCardsto return articles based on theArticlegrn we passed into the request parameters.
Continuous Processing
Continuous Processing (CP) allows for event-based processing of text nodes that are dropped directly onto the graph. CP requires a message broker and currently the only supported broker is RabbitMQ. There are future plans to implement SQS and Kafka for Continuous Processing.
Continuous Processing has similar inner workings to GraphGrid Search's "Continuous Indexing" pipeline, though this is considerably simpler.
We can use CP to automatically start the data processing process for any new article nodes that are added to the graph. To set this up, simply use the Continuous Processing Trigger endpoint.
You will need the name of the document policy you created and the corpus grn. To easily find the corpus grn run this query in ONgDB:
MATCH (n:Corpus) RETURN n.grn
curl --location --request POST "${API_BASE}/1.0/nlp/default/continuousProcessingTrigger/gg-dev-document-policy" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}" \
--data-raw '{
"corpusGrn": "grn:gg:corpus:xjSR1yr4u08ERPxxcBKpgQpeZF1wvEbm3JYb3UeAkUcV",
"processor": "bert"
}'
If Continuous Processing is enabled, running the manual fullDataExtraction and partialDataExtraction endpoints may result in double annotation. See
more about Continuous Processing and possible pitfalls here.
To check if CP is enabled and to see information about the processing trigger, use this Geequel query in ONgDB:
CALL apoc.trigger.list
This will return a list of all the apoc triggers that are running. You should see the name of the continuousProcessing policy and a query that looks like this:
"WITH {createdNodes} AS createdNodes UNWIND createdNodes AS createdNode WITH createdNode WHERE createdNode:`Article` AND NOT createdNode:`Translation` WITH collect(createdNode.grn) AS batchedNodeIds WITH batchedNodeIds, ' CALL apoc.broker.send(\'rabbitmq\',{numTries: \'0\', transactionId: timestamp(), label: \'Article\', property: \'content\', corpusGrn: \'grn:gg:corpus:xjSR1yr4u08ERPxxcBKpgQpeZF1wvEbm3JYb3UeAkUcV\', processor: \'BERT\', idPartition: \''+apoc.convert.toString(batchedNodeIds)+'\' }, {config} ) YIELD connectionName AS `_connectionName`, message AS `_message`, configuration AS `_configuration` RETURN 1' AS brokerCall CALL apoc.cypher.doIt(' WITH {brokerCall} AS brokerCall, {batchedNodeIds} AS batchedNodeIds, {config} AS config CALL apoc.do.when(coalesce(size(batchedNodeIds) > 0, false), brokerCall, \'\', {brokerCall: {brokerCall}, batchedNodeIds:{batchedNodeIds}, config: {config}}) YIELD value RETURN value', {brokerCall: brokerCall, batchedNodeIds:batchedNodeIds, config: {config} } ) YIELD value AS brokerDoIt RETURN 1"
If you wish to remove the processing trigger run:
CALL apoc.trigger.remove("<trigger_name>")
When used in conjunction with a continually ingesting source, this allows for a full pipeline from direct source to processed text data with full feature capabilities. Click here to follow a tutorial on how to set up a continuous processing trigger with RSS Ingest.
Key Information
Avoid common pitfalls by familiarizing yourself with this information regarding NLP data processing:
fullDataExtractionis only to be used when there are noAnnotatedTextnodes on the graph. If there are already annotated nodes on the graph, runningfullDataExtractionwill cause NLP to process those article nodes again and create a duplicateAnnotatedTextnode. For the first pass with fresh data, we can usefullDataExtraction.- If new data is added to the graph after the first pass of data processing, use the
partialDataExtractionendpoint..partialDataExtractionwill only process the article nodes that do not haveAnnotatedTextnodes. NLP is also able to utilize a message broker forcontinuousProcessingwhich runs the data processing process automatically. - Data processing takes a variable amount of time. To check data processing progress, run
MATCH (a:Article)-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText) RETURN a, atin ONgDB and check to see if the article nodes have anAnnotatedTextnode. Once each of the nodes has anAnnotatedTextnode, NLP is finished processing. You can also check the NLP logs usingdocker-compose logs -f nlpto follow NLP's progress. The last step in the process is summarizing the text nodes. The process is finished when you seeSUMMARY_SENTENCErelationships. - If Continuous Processing is enabled, running the manual
fullDataExtractionandpartialDataExtractionendpoints may result in double annotation. See more about Continuous Processing and possible pitfalls here - Check if CP is enabled by running
CALL apoc.trigger.listin ONgDB and look for the trigger name ending with "continuousProcessing".