GraphGrid NLP
2.0API Version 1.0
Introduction
GraphGrid Natural Language Processing (NLP) provides a domain for graph-based data processing. This service uses text-to-graph data extraction along with a variety of natural language processing features. By analyzing text, GraphGrid NLP can interpret and extract a text data structure and store it in a graph database. This means that processed text data is formed into a graph database representation. This extraction, along with several NLP features, forms a framework of tools for real-time text processing in several different languages; as well as analysis capable of determining the evolution of articles/text data over time.
Most of these examples require an Article node to exist on the graph. Content can be added to the graph
using the Ingest service, or manually using Geequel. See here for an example. Additionally, corpusGrn
can be found by running the following Geequel MATCH (n:Corpus) RETURN n
Environment
NLP requires the following integrations:
- GraphGrid Config
- GraphGrid Fuze
- RabbitMQ
- ONgDB 1.0+
- Elasticsearch
API
This NLP API version is 1.0 and as such all endpoints are rooted at /1.0/nlp/. For example, http://localhost/1.0/nlp (requires auth) would be the
base context for this NLP API under the GraphGrid API deployed at http://localhost.
The API uses simple http authentication with a username and password that is stored/retrieved from param-store under spring.security.user.name and
spring.security.user.password for that NLP environment.
NLP GPU Usage
NLP data extraction performs at a higher speed when using GraphGrid GPU support. GPU support is disabled by defualt but can be endabled using the GraphGrid CLI command:
./bin/graphgrid gpu enable
Find for more information about GPU support here.
Status
Check the status of GraphGrid NLP. Will return a 200 OK response if healthy.
Base URL: /1.0/nlp/status
Method: GET
Request
curl --location --request GET "${API_BASE}/1.0/nlp/status"
Response
200 OK
Features Overview
GraphGrids Natural Language Processing application offers several language processing features including:
- Data Extraction (Text → Graph)
- Document Similarity Scoring
- Document Summarization
- Document Origination
- Paraphrase Detection
In this section we layout a small overview of each feature, their relevant API endpoints, and proceeding sections delve into internal workings of the features.
Data Extraction
Data extraction (or Annotating text) is the process by which text is turned into a graph structure. Nodes representing text to be processed are used by GraphGrid NLP to create a graphical representation of the original text. This representation inside the graph is the basis for all of GraphGrid NLP's other language processing features.
GraphGrid NLP uses models that are fine-tuned from a BERT base; an autoencoding model best suited for information extraction, distillation, and other analytical tasks.
There are two options for data extraction, full and partial extraction. Full data extraction will run processing on all of the defined text-based nodes regardless if they have been annotated already. Partial extraction will only run processing on the deinfed text-based nodes if they have not been annotated.
Full Data Extraction
Runs data extraction on all defined text-based node labels.
Base URL: /1.0/nlp/fullDataExtraction
Method: POST
Request
curl --location --request POST "${API_BASE}/1.0/nlp/fullDataExtraction" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}" \
--data-raw '{
"label": "Article",
"property": "content"
}'
Response
200 OK
Partial Data Extraction
Runs data extraction on only the defined text-based data node labels that have not already been annotated.
Base URL: /1.0/nlp/partialDataExtraction
Method: POST
Request
curl --location --request POST "${API_BASE}/1.0/nlp/partialDataExtraction" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}" \
--data-raw '{
"label": "Article",
"property": "content"
}'
Response
200 OK
Document Similarity Scoring
Document similarities are scored based on a Term Frequency-Inverse Document Frequency (TF-IDF) method. (However, instead of looking at all the words in a corpus
and a document, we only look at the important words, i.e. Mentions.) We embed each document in a corpus based on their tf-idf vectors, and are then able to
calculate how similar two documents are. This is a standard method for computing document similarity. Term-frequency is calculated once per document and stored on
the graph in HAS_TF relationships, while inverse-document frequency is calculated as needed.
Document Origination
One of the more unique features offered by GraphGrid NLP is the ability to take a document and form a story-arch, an ordered list of documents that come from one another. This feature assists analyzers by tracking a story and its context over its lifespan.
Origination Raw
Provides a comparison of two texts, and tries to determine if textB originated from textA. A sentence similarity
matrix is also provided.
Base URL: /1.0/nlp/originationRaw
Method: POST
| Parameter | Description |
|---|---|
| textA string | Contents of the first text to compare against. |
| textB string | Contents of the second text. |
Request
curl --location --request POST "${API_BASE}/1.0/nlp/originationRaw" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}" \
--data-raw '{
"textA": "(CNN)The United States and Russian navies are at odds over an apparent near collision in the Pacific Friday with each side blaming the other. The US and Russian warships came somewhere between 50 feet and 165 feet of each other, according to the two opposing reports, with both sides alleging their ships were forced to perform emergency maneuvers to avoid a collision. This latest incident comes just days after the US Navy accused Russia of intercepting a US aircraft and amid tensions with Moscow on a wide range of geopolitical issues. Last month, Secretary of State Mike Pompeo met Russian Vladimir Putin in the resort town of Sochi, where he warned Russia about interfering in US elections, taking a tougher public line than President Donald Trump on the issue. \"A Russian destroyer .... made an unsafe maneuver against USS Chancellorsville, closing to 50-100 feet, putting the safety of her crew and ship at risk,\" US Navy spokesman Cmdr. Clayton Doss told CNN in a statement. \"This unsafe action forced Chancellorsville to execute all engines back full and to maneuver to avoid collision,\" Doss said. The US guided-missile cruiser was traveling in a straight line and trying to recover its helicopter when the incident occurred, he said. \"We consider Russia'\''s actions during this interaction as unsafe and unprofessional,\" Doss said. The US account was contradicted by Russia'\''s Pacific Fleet, which claimed it was the US ship that instigated the incident, according to comments carried by the state-run RIA-Novosti news agency. CNN has obtained a picture of the event after a US official told CNN earlier that the Navy was working to declassify images to dispute the Russian narrative that the US was at fault. Two navy officials tell CNN the Russian wake in the photo could only come from a steep turn that has to be executed at high speed. \"When moving (on) parallel courses of a detachment of ships of the Pacific Fleet and a carrier group of the US Navy, the cruiser Chancellorsville suddenly changed its direction and crossed within 50 meters of the Admiral Vinogradov,\" forcing the Russian destroyer to take emergency evasive action, the RIA-Novosti report said. The US Navy said the incident occurred in the Philippine Sea while the Russian report said it happened in the East China Sea. The boundary between the two bodies of water is the Senakaku Islands (also known as the Diaoyu islands in China), to the south of Japan and east of Taiwan. Regardless, the incident occurred in international waters and unusually far away from Russia, according to Carl Schuster, a retired US Navy captain and former director of operations at the US Pacific Command'\''s Joint Intelligence Center. \"The Russians normally harass our ships when they are operating in waters the Russian consider to be within their sphere of Influence (Black Sea, Barents Sea and the waters off Validvostok,\" said Schuster, who spent 12 years at sea on US warships. \"Putin clearly has ordered the Russian Navy to pressure the USN whenever opportunities exist. It may possibly be a show of political support for China while Xi is in Moscow, but more likely to signal that Russia is willing to challenge the US dominance on the world stage and at sea,\" he said. International maritime law requires ships to maintain a safe distance, normally interpreted as 1,000 yards, when passing another, Schuster added. It also requires navies not to interfere with another ship conducting flight operations, he said. On Tuesday, the US accused Russia of intercepting a US aircraft flying in international airspace over the Mediterranean Sea three times in just under three hours. The second of the three interactions \"was determined to be unsafe\" due to the Russian aircraft \"conducting a high speed pass directly in front of the mission aircraft, which put our pilots and crew at risk,\" the US Navy said.",
"textB": "The U.S. Navy accused a Russian ship of \"unsafe and unprofessional\" conduct after an incident Friday in the Philippine Sea caused a near-collision between a Russian destroyer and the American guided missile cruiser USS Chancellorsville. The Russian Pacific Fleet countered that it was the U.S. vessel that had engaged in dangerous maneuvering, forcing the Russian destroyer Admiral Vinodgradov to take emergency action, Russia's Interfax news agency reported. According to Cmdr. Clay Doss of the U.S. 7th Fleet, the Chancellorsville was recovering its helicopter while maintaining a steady course when the Russian ship came from behind and \"accelerated and closed to an unsafe distance\" of about 50 to 100 feet. \"This unsafe action forced Chancellorsville to execute all engines back full and to maneuver to avoid collision,\" Doss said in a statement. \"We consider Russia's actions during this interaction as unsafe and unprofessional.\" The Russian statement, however, said the U.S. cruiser \"suddenly changed directions and came within 50 meters [164 feet] of the Russian destroyer.\" Since January 2018, the Pentagon has been implementing a new long-term strategy that refocuses the U.S. military on competition with Russia and China, which have both been building up and modernizing their militaries and challenging the United States' once unquestioned naval supremacy. It was the second close brush between Russian and U.S. forces this week. On Tuesday, the Navy's 6th Fleet said a Russian Su-35 fighter plane flew \"directly in front\" of a U.S. Navy P-8A Poseidon over the eastern Mediterranean. There were no injuries or harm to the planes, but the Navy called the Russian interception an \"irresponsible\" action that \"put our pilots and crew at risk.\" Fleets belonging to Russia and NATO regularly trade barbs over what each side says are infringements on their course in international waters - although they usually take place on the other side of the globe from the Pacific. In October, a Chinese destroyer came within yards of a U.S. Navy ship conducting so-called \"freedom of navigation\" missions near disputed islands claimed by China but not recognized as Chinese territory by the rest of the world. The USS Decatur was forced to change course to avoid a collision. China has described the presence of U.S. ships in these areas as a threat to its sovereignty. The incident comes as Russia is hosting Chinese President Xi Jinping and a massive business delegation at a glitzy economic forum in St. Petersburg. The leaders of the two countries have been heaping praise on each other, with Xi calling President Vladimir Putin his \"best and bosom\" friend. Both Russia and China are in economic battles with the United States involving sanctions and tariffs."
}'
Load Word Embedding Model
Base URL: /1.0/nlp/{{clusterName}}/loadWordEmbeddingModel/{{wordEmbeddingModel}}
Method: GET
| Parameter | Description |
|---|---|
| clusterName string | The name of the cluster. |
| wordEmbeddingModel string | The model to embed. |
The word embedding model file should exist in S3/MinIO. The bucket is determined by the spring.aws.nlp.s3.bucket-name config value.
The file should be in that bucket at /gg/{{clusterName}}/resources/{{wordEmbeddingModel}}
Request
curl --location --request GET "${API_BASE}/1.0/nlp/gg-prod-default/loadWordEmbeddingModel/paragram_sl999_czeng.txt" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}"
Response
200 OK
Get Word Embedding Model Report
Base URL: /1.0/nlp/{{clusterName}}/getWordEmbeddingModelReport
Method: GET
| Parameter | Description |
|---|---|
| clusterName string | The name of the cluster. |
Request
curl --location --request GET "${API_BASE}/1.0/nlp/gg-prod-default/getWordEmbeddingModelReport" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}"
Response
{
"cluster": "gg-prod-default",
"model": "paragram_sl999_czeng.txt",
"embedding size": 300,
"vocabulary size": 77288
}
Story Arch Origination
Base URL: /1.0/nlp/{{clusterName}}/storyArchOrigination/{{documentPolicyName}}/{{corpusGrn}}/{{nodeGrn}}
Method: GET
| Parameter | Description |
|---|---|
| clusterName string | The name of the cluster. |
| documentPolicyName string | The name of the document policy. |
| corpusGrn string | The grn of the corpus node. |
| nodeGrn string | The grn of the annotatedText node. |
Request
{
curl --location --request GET "${API_BASE}/1.0/nlp/default/storyArchOrigination/gg-dev-document-policy/grn:gg:corpus:67TMS82T8xCvyK2rAxkqxntGW9jISAeHVg4WZlQi6rnq/grn:gg:article:EYTNI5YlNKgwYqpAUI84hhk7sUpgAEoOUWwUeNIRG4Qh" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}"
}
Response
[
{
"grn": "grn:gg:article:EYTNI5YlNKgwYqpAUI84hhk7sUpgAEoOUWwUeNIRG4Qh",
"publishDate": "2021-04-01T15:30:59Z",
"language": "en",
"imageUrl": null,
"title": "Geequel-Graph Query Language for the People!",
"summary": "The intent with Geequel is to implement all of GQL and a big portion of openCypher® (openCypher® is a trademark of Neo4j, Inc.)\n Geequel is an implementation of openCypher®, the most widely adopted, fully-specified, and open query language for property graph databases. Geequel provides an intuitive way to work with ONgDB, a property graph, and is a great on-ramp to the Graph Query Language (GQL) standard being developed by ISO. Geequel is ONgDB's powerful Graph Query Language. Geequel looks a lot like ASCII art because it uses textual pattern representations to express nodes and relationships.",
"fullText": "Geequel is ONgDB's powerful Graph Query Language. It is a declarative, pattern matching language optimized for querying graph networks. Geequel is an implementation of openCypher®, the most widely adopted, fully-specified, and open query language for property graph databases. Geequel provides an intuitive way to work with ONgDB, a property graph, and is a great on-ramp to the Graph Query Language (GQL) standard being developed by ISO. Geequel is easy to learn and human-readable, making Geequel approachable, useful and unifying for business analysts, data scientists, software developers and operations professionals. The declarative nature of Geequel allows users to simply express the data they wish to retrieve while the underlying Geequel query runtime completes the task without burdening the user with Geequel implementation details. Geequel is one of the most powerful ways to effectively express graph database traversals for reading and writing data into ONgDB. Geequel makes it possible to direct ONgDB to do something like: "bring back my friends' friends right now" or "starting with this employee return their full reporting chain" in the form of several code lines. As such, Geequel queries and operations across all languages and integrations with ONgDB are able to query in a consistent manner. Geequel looks a lot like ASCII art because it uses textual pattern representations to express nodes and relationships. The nodes are surrounded with parenthesis which appear like circles and the relationships consist of dashes with square brackets. Here's an example: (graphs)-[:ARE]-(everywhere). Writing and representing depth based queries is one place where Geequel shines. To look at the friends of my friend's friends is as simple as "(me)-[:FRIEND*3]->(fofof). It is actually fun to create queries because the declarative nature of Geequel follows direct patterns and relationships without having to think about what needs joining together to aggregate the required data. In an RDBMS implementation with SQL, the queries mentioned above would involve a lot of code to write and perform poorly due to the number of joins. But with Geequel on ONgDB, it is possible to represent complex ideas with minimal code and optimized traversal performance at the same time. The intent with Geequel is to implement all of GQL and a big portion of openCypher® (openCypher® is a trademark of Neo4j, Inc.)\n",
"source": "graphfoundation",
"sourceUrl": "https://www.graphfoundation.org/geequel/",
"sentiment": 0.3888888888888889,
"trustScore": null,
"tags": [
"openCypher ®",
"Graph Query Language",
"ONgDB",
"Geequel",
"Inc .",
"[UNK] Graph Query Language",
"Neo4j",
"openCypher"
],
"knowledgeGraphEntities": [
"grn:gg:knowledgegraphentity:zcbhLThStPhhdBXJ4M7GqJ3dHkG4nntBZ0exJIRlUMXO",
"grn:gg:knowledgegraphentity:XuiGtMUgPeeh40p1evpbUFzE2DtJFcqlfa6ovsMrx1O6",
"grn:gg:knowledgegraphentity:47v26SDONDLsoJU9henwQT0HWdnqcAxslazu1ZsmQi7I",
"grn:gg:knowledgegraphentity:Ke1jZsWrpQtJrkOYFOiiqROGUE2ojT2JDnKDnWlI93aw",
"grn:gg:knowledgegraphentity:3QBudEEwHsa64U33eSOaNzeTuhMaAdjee5twLFgSZBaB",
"grn:gg:knowledgegraphentity:bZ75oM6rB2xeI9i8NdttvGzxg6aj0NEGHcTp3PBTQ9p0"
],
"translatedFullText": null,
"translatedTitle": null,
"nativeTextGrn": null
}
]
Paraphrase Detection
Paraphrase Detection serves as the backbone of Document Origination. It can also be used as its own feature. Two documents are embedded into sentence vectors and compared for paraphrasing of one another. This can be used to detect uncanny similarities in texts.
Document Summarization
GraphGrid NLP offers automated document summarization through extractive techniques. A document's summary is composed of the k most relevant sentences. A sentence's relevancy is determined by the average of its word's tf-idf score (for normalization).
Summarize Single Text in Corpus
Summarize one specific AnnotatedText node in a corpus.
Base URL: /1.0/nlp/summarizeText/{{corpusGrn}}/{{nodeLabel}}/{{nodeGrn}}/{{maxSummaryLength}}
Method: POST
| Parameter | Description |
|---|---|
| corpusGrn string | The grn of the corpus node. |
| nodeLabel string | The label of the annotatedText node |
| nodeGrn string | The grn of the annotatedText node |
| maxSummaryLength string | The maximum number of sentences to include in the summary for the specified document. |
Request
curl --location --request POST "${API_BASE}/1.0/nlp/summarizeText/grn:gg:corpus:67TMS82T8xCvyK2rAxkqxntGW9jISAeHVg4WZlQi6rnq/Article/grn:gg:article:RjsZUvOWHEHvGtZhQzHLk0FvXnF6Dop2XWLLluVsCdcY/5" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}"
Response
{
"grn:gg:sentence:EcU4Cf2boN9CtGgB1opQo4gtkMsVwiH2OfwLAY3rnixm": {
"text": "Key advantages Open Native Graph Database (ONgDB) offers for enterprises include: Referential Integrity: ONgDB is a reliable, scalable and high-performing native graph database that is suitable for enterprise use. ",
"order": 2
},
"grn:gg:sentence:KOd1gF9wVZjV0lQBSnyxHDRSujpb0ukCTrNydbrdSUVI": {
"text": "Cache Sharding: ONgDB provides scale-out, in-memory read sharding to allow a high cache hit ratio where reads that are relevant to each instance in the cluster will warm the cache without needing to load the whole graph into memory. ",
"order": 1
},
"grn:gg:sentence:dp22vUoSr7qmmNcJJpmTfXNXg33fE0xvJmxWAjDvIn2i": {
"text": "For many use cases, ONgDB will provide orders of magnitude performance benefits compared to non-native graph, relational and NoSQL databases. ",
"order": 3
},
"grn:gg:sentence:JpFVTxMpOpVgywgL3kOA2zliYbtFc15I42PFZzpP7b1S": {
"text": "ONgDB ensures that operations involving the modification of data happen within a transaction to guarantee consistent data. ",
"order": 4
},
"grn:gg:sentence:740CTJu0AMaHOVUqm1q7v8mF9gQdTzU0ZYnOMjBWRF41": {
"text": "Agility: Creating with Open Native Graph Database perfectly aligns with with lean interactive development practices, which lets your graph database evolve with the rest of the application and evolving business needs. ",
"order": 0
}
}
Summarize Texts in Corpus
Get the extracted summary of all texts in a specific corpus.
Base URL: /1.0/nlp/summarizeTexts/{{corpusGrn}}/{{nodeLabel}}/maxSummaryLength
Method: GET
| Parameter | Description |
|---|---|
| corpusGrn string | The grn of the corpus node. |
| maxSummaryLength string | The maximum number of sentences to include in the summary of each document in the corpus |
Request
curl --location --request GET "${API_BASE}/1.0/nlp/summarizeTexts/grn:gg:corpus:67TMS82T8xCvyK2rAxkqxntGW9jISAeHVg4WZlQi6rnq/Article/5" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}" \
--data-raw '{
"excludeTextsWithSummaries": false
}'
Response
{
"grn:gg:article:RjsZUvOWHEHvGtZhQzHLk0FvXnF6Dop2XWLLluVsCdcY": {
"grn:gg:sentence:EcU4Cf2boN9CtGgB1opQo4gtkMsVwiH2OfwLAY3rnixm": {
"text": "Key advantages Open Native Graph Database (ONgDB) offers for enterprises include: Referential Integrity: ONgDB is a reliable, scalable and high-performing native graph database that is suitable for enterprise use. ",
"order": 2
},
"grn:gg:sentence:KOd1gF9wVZjV0lQBSnyxHDRSujpb0ukCTrNydbrdSUVI": {
"text": "Cache Sharding: ONgDB provides scale-out, in-memory read sharding to allow a high cache hit ratio where reads that are relevant to each instance in the cluster will warm the cache without needing to load the whole graph into memory. ",
"order": 1
},
"grn:gg:sentence:dp22vUoSr7qmmNcJJpmTfXNXg33fE0xvJmxWAjDvIn2i": {
"text": "For many use cases, ONgDB will provide orders of magnitude performance benefits compared to non-native graph, relational and NoSQL databases. ",
"order": 3
},
"grn:gg:sentence:JpFVTxMpOpVgywgL3kOA2zliYbtFc15I42PFZzpP7b1S": {
"text": "ONgDB ensures that operations involving the modification of data happen within a transaction to guarantee consistent data. ",
"order": 4
},
"grn:gg:sentence:740CTJu0AMaHOVUqm1q7v8mF9gQdTzU0ZYnOMjBWRF41": {
"text": "Agility: Creating with Open Native Graph Database perfectly aligns with with lean interactive development practices, which lets your graph database evolve with the rest of the application and evolving business needs. ",
"order": 0
}
},
"grn:gg:article:EYTNI5YlNKgwYqpAUI84hhk7sUpgAEoOUWwUeNIRG4Qh": {
"grn:gg:sentence:j1U8fEfoL83I24sVyBcqthdcdTSZjwtkJqQf88bq8QAy": {
"text": "Geequel provides an intuitive way to work with ONgDB, a property graph, and is a great on-ramp to the Graph Query Language (GQL) standard being developed by ISO. ",
"order": 2
},
"grn:gg:sentence:9PXd7VfXfUIMbfe4Bes4BQuVVuCzcypSAhW6SLZ4IzQp": {
"text": "The intent with Geequel is to implement all of GQL and a big portion of openCypher® (openCypher® is a trademark of Neo4j, Inc.)\n",
"order": 0
},
"grn:gg:sentence:qZ1GdDmsWKrH8YuddlLAyytuVNhcwfXY0jmsDuSuljkJ": {
"text": "Geequel is an implementation of openCypher®, the most widely adopted, fully-specified, and open query language for property graph databases. ",
"order": 1
},
"grn:gg:sentence:uz6vNyWjhj19WIz0jjuwZ7bji3HPjnwGg5lHWPyz4mKs": {
"text": "Geequel is ONgDB's powerful Graph Query Language. ",
"order": 3
},
"grn:gg:sentence:XF0e5EUrLO20pzeuJyti5lBfuEjbGXiWioZU2PqVFAbH": {
"text": "Geequel makes it possible to direct ONgDB to do something like: "bring back my friends' friends right now" or "starting with this employee return their full reporting chain" in the form of several code lines. ",
"order": 4
}
}
}
NLP Metrics
The nlpMetrics endpoint takes in the node grn of either an annotatedText or a corpus and returns NLP Metrics. If an annotatedText node is used, the endpoint will return the metrics for that node's text. If a corpus node is used, the endpoint will return metrics for each annotatedText node in that corpus. Users can easily get an annotatedText grn from a text from this endpoint or a corpus grn from this endpoint.
Base URL: /1.0/nlp/getNLPMetric/{{annotatedText or corpus grn}}
Method: GET
| Parameter | Description |
|---|---|
| annotatedText grn | The grn of the annotatedText node. |
| corpus grn | The grn of the corpus node. |
The request body includes the following data options:
- Filter: There is currently one type in place;
TimeRangeFilterhas astartTimeandendTime, and will shownlpMetricsfrom only theannotatedTexts that were created within that time range.startTimeandendTimeare strings that must be in the following format:yyyy-MM-ddTHH:mm:ss.SSZ - Order: Gives the option to sort
nlpMetricsbased on the time at which their respectiveannotatedTexts were created (TIME_EARLIESTsorts from earliest to most recent,TIME_LATESTsorts the opposite way- from most recent to earliest). - Aggregators: Rather than returning a list of all
nlpMetrics, passing in aggregators will provide aggregate information (min,max, and/oravg) for each of the two properties (totalTimeElapsedandnumberOfWords). If aggregators are passed in that do not exist, users will recieve a message in the response that says:"No valid aggregators found. Valid aggregators are 'min', 'max', and 'avg'"
Here are a few examples of how the textMap that the endpoint accepts may look:
{
"filter": {"startTime":"2023-01-20T10:00:00.00Z", "endTime":"2023-05-15T12:00:00.00Z"},
"order": "TIME_LATEST",
"aggregators": []
}
{
"filter": {"startTime":"2023-01-20T10:00:00.00Z", "endTime":"2023-05-15T12:00:00.00Z"} ,
"aggregators": ["avg"]
}
{
"aggregators": ["min", "max", "avg"]
}
Request Example for nlpMetrics using Corpus without Aggregators
curl --location --request GET '${API_BASE}/1.0/nlp/getNlpMetric/grn:gg:corpus:default' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer ${BEARER_TOKEN}' \
--data-raw '{
"filter": {
"startTime":"2020-01-20T10:00:00.00Z",
"endTime":"2025-05-15T12:00:00.00Z"
},
"order": "TIME_LATEST",
"aggregators": []
}'
Response Example for nlpMetrics using Corpus grn without Aggregators
This example shows a response from a request when a corpus grn is provided, where an annotatedText with its respective nlpMetrics is returned:
{
"nlpMetricMap": {
"grn:gg:annotatedtext:ec9wxfHipnrpcrCJOb55v587Rl7YlZ14gMEurf2jwb3w": {
"totalTimeElapsed": 15.609,
"numberOfWords": 86
}
},
"aggregatorMap": {}
}
Request Example for nlpMetrics using Corpus grn with Aggregators
curl --location --request GET '${API_BASE}/1.0/nlp/getNlpMetric/grn:gg:corpus:default' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer ${BEARER_TOKEN}' \
--data-raw '{
"filter": {
"startTime":"2024-01-23T16:38:41.00Z",
"endTime":"2025-01-24T16:38:44.00Z"
},
"order": "TIME_LATEST",
"aggregators": ["min","max","avg"]
}'
Response Example for nlpMetrics using Corpus with Aggregators
{
"nlpMetricMap": {
"grn:gg:annotatedtext:OLc5RKvhbdUEIbrjrluaBTF8HmLKfjX3Kt2J8NEPtIEy": {
"totalTimeElapsed": 15.493,
"numberOfWords": 36
},
"grn:gg:annotatedtext:bl6jqhZzhQVUjDESRdjGgvkX6Dr45oWyTFOvXzk4k6f2": {
"totalTimeElapsed": 1.469,
"numberOfWords": 8
},
"grn:gg:annotatedtext:QB09Jmfyp1jaHg5W83XxHOruOciNyaGeRFk3ruEGgqOn": {
"totalTimeElapsed": 2.387,
"numberOfWords": 9
},
"grn:gg:annotatedtext:ec9wxfHipnrpcrCJOb55v587Rl7YlZ14gMEurf2jwb3w": {
"totalTimeElapsed": 15.609,
"numberOfWords": 86
}
},
"aggregatorMap": {
"minTotalTimeElapsed": 1.469,
"minNumberOfWords": 8.0,
"maxNumberOfWords": 86.0,
"avgTotalTimeElapsed": 8.7395,
"avgNumberOfWords": 34.75,
"maxTotalTimeElapsed": 15.609
}
}
Request Example for nlpMetrics using AnnotatedText grn
curl --location --request GET '${API_BASE}/1.0/nlp/getNlpMetric/grn:gg:annotatedtext:ec9wxfHipnrpcrCJOb55v587Rl7YlZ14gMEurf2jwb3w' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer ${BEARER_TOKEN}' \
--data-raw '{
"filter": {
"startTime":"2024-01-23T16:38:41.00Z",
"endTime":"2025-01-24T16:38:44.00Z"
}
}'
Response Example for AnnotatedText
{
"nlpMetricMap": {
"grn:gg:annotatedtext:ec9wxfHipnrpcrCJOb55v587Rl7YlZ14gMEurf2jwb3w": {
"totalTimeElapsed": 15.609,
"numberOfWords": 86
}
},
"aggregatorMap": {}
}
Get AnnotatedText grn from Text
Get annotatedText grns out of the graph without having to run a query.
Base URL: /1.0/nlp/getNLPMetric/getAnnotatedTextGrnFromText
Method: GET
Request body
This request takes the following request body:
{
"nodeType": <label for the type of node that contains text that was nlp processed (String)>,
"propertyName": <name of the property that user wants to be searched (String)>,
"propertyValue": <the value of that property that will be searched for (String)>
}
For example:
{
"nodeType": "Article",
"propertyName": "title",
"propertyValue": "Big Bad Wolf"
}
The response will return:
[
{
"<propertyName>": "<propertyValue>",
"<nodeType>Grn": <grn>
"AnnotatedTextGrn": [<list of annotatedText grns>]
},
{
"<propertyName>": "<propertyValue>",
"<nodeType>Grn": <grn>
"AnnotatedTextGrn": [<list of annotatedText grns>]
},
...
]
e.g.
[
{
"title": "Big Bad Wolf",
"ArticleGrn": "some-article-grn"
"AnnotatedTextGrn": ["some-annotated-text-grn"]
}
]
The number of maps in the return depends on how many nodes of the given type were found with the same given property (e.g. how many Article nodes were found with the title "Big Bad Wolf").
Request
curl --location --request GET 'http://localhost/1.0/nlp/getAnnotatedTextGrnFromText' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer bdb1bd69-b704-413b-b5af-53b98d895241' \
--data-raw '{
"nodeType": "Article",
"propertyName": "title",
"propertyValue": "Superstores"
}'
Response
[
{
"AnnotatedTextGrn": [
"grn:gg:annotatedtext:OLc5RKvhbdUEIbrjrluaBTF8HmLKfjX3Kt2J8NEPtIEy"
],
"ArticleGrn": "grn:gg:article:69kHjsVRsrU2SVVZNINblgaqz9tiEIJ5GZkfyEG58aCW",
"title": "Superstores"
}
]
Get Available Corpora
Returns a list of the corpus nodes in the graph.
Base URL: /1.0/nlp/corpus/availableCorpora
Method: GET
Request
curl --location --request GET '${API_BASE}/1.0/nlp/corpus/availableCorpora' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer ${BEARER_TOKEN}' \
Response
[
{
"id": 42,
"labels": [
"GraphGridResource"
],
"enver": 0,
"createdAt": "2023-11-09T16:53:50.5350Z",
"updatedAt": "2023-11-09T16:53:50.5350Z",
"createdBy": "graphgrid",
"lastModifiedBy": "graphgrid",
"grn": "grn:gg:corpus:default",
"name": "default",
"grnType": "corpus",
"label": "Corpus"
}
]
Domain Overview
This section gives a brief description of GraphGrid NLP's node labels and relationship types in the context of the Data Extraction process.
Graphgrid NLP Domain
GraphGrid NLP's domain forms a graph database representation for a processed text.
Nodes
The nodes in the domain include:
- AnnotatedText nodes
- Sentence nodes
- Mention / NER nodes
- MentionOccurrence nodes
- Corpus nodes
- Sentiment node types
AnnotedText nodes
AnnotatedText nodes represent the processed text as a whole. They can be thought of as a representation of the original document, without disrupting the original
graph structure. They serve as the "head" of the data extraction tree.
Sentence nodes
As their name implies, Sentence nodes represent sentences. Sentence nodes hold the text of the sentences and are connected to AnnotatedText nodes, Mention nodes,
and MentionOccurrence nodes.
Mention nodes / NER nodes
Mention and NER (named entity recognition) nodes represent the entities in a text. Mention is the superlabel of NER labels, and groups the NER labels together.
Some examples of NER labels are:
- NER_Person
- NER_Location
- NER_Organization
- NER_Misc
The NER labels listed here are only available when using BERT based data extraction; If using CoreNLP there are more NER labels. A Mention node can have multiple
NER labels. Mention nodes represent the abstract object, while MentionOccurrence represents an actual occurrence of a mention. Mentions are "global" meaning that
in a graph an entity should only be represented by a single Mention node.
MentionOccurrence nodes
MentionOccurrence (MO) nodes represent a single occurrence of a mention. A MO may have a different value from its corresponding Mention node. For example a MO
may have a value of "John" while its corresponding Mention node has the value "John Smith". A Mention node can have multiple connecting MO nodes, but each MO only
has one corresponding Mention node.
Corpus nodes
The word corpus means a collection of documents. Our Corpus node represents a collection of AnnotatedText nodes. It provides the context around any single AnnotatedText node. The corpus is very important to the features that GraphGrid NLP provides, and it is used in most of them. An AnnotatedText node must be connected to at least one Corpus node, but may be connected to multiple.
Sentiment node types
Sentiment nodes (AnnotatedTextSentiment and SentenceSentiment) contain the calculated sentiment. Sentiment is calculated by a neural network at a sentence level. The sentence sentiments are then averaged to compute an article's entire sentiment.
Relationships
There are many types of relationships that connect the nodes in our domain.
CONTAINS_SENTENCE/FIRST_SENTENCE
These are two relationships between AnnotatedText nodes and Sentence nodes. A CONTAINS_SENTECE relationship goes out from an AnnotatedText node to a Sentence node. The Sentence node representing the first sentence of the AnnotatedText also has a FIRST_SENTENCE relationship.
NEXT_SENTENCE
This relationship is between two Sentence nodes and is used to represent the order of the sentences in a text.
CONTAINS_ANNOTATED_TEXT
This is a relationship from a Corpus node to an annotatedText node. It tells us that the Corpus contains that annotatedText.
HAS_MENTION / MENTION_OCCURENCE_MENTION / SENTENCE_MENTION_OCCURENCE
The relationship HAS_MENTION goes from a Sentence node to a Mention node. It means that a Sentence contains a reference to the entity represented by the Mention node.
The relationship MENTION_OCCURRENCE_MENTION goes from a Mention node to a MentionOccurrence node. This relationship connects a Mention to its occurrence. The relationship SENTENCE_MENTION_OCCURRENCE goes from a Sentence node to a MentionOccurrence node. This relationship connects a Sentence to an occurrence.
HAS_ANNOTATED_TEXT
This relationship goes from a "text" node (see Interacting with the existing graph) to an
AnnotatedText node. The relationship means that the text node is represented by that AnnotatedText node.
HAS_SENTIMENT
This relationship has two usages, each connecting a node with its sentiment node.
- Going from a Sentence node to a
SentenceSentimentnode - Going from an
AnnotatedTextnode to aAnnotatedTextSentimentnode.
SUMMARY_SENTENCE
This relationship, going from an AnnotatedText to a Sentence, marks a sentence as part of the automated document summary. This relationship has a property order
which represents the placement of the sentence in the summary.
HAS_TF
See Document Similarity Scoring for an explanation of Term Frequency-Inverse Document Frequency.
KBP Relation Relationships
These are a special group of relationships between Mentions in the graph that have been extracted from the text. These relations include:
"alternate_names", "city_of_headquarters", "country_of_headquarters", "founded", "founded_by", "members", "stateorprovince_of_headquarters", "subsidiaries", "top_members/employees", "alternate_names", "cities_of_residence", "countries_of_residence", "country_of_birth", "employee_of", "origin", "spouse", "stateorprovinces_of_residence", "title", "no_relation"
Save Document Policy
Request
curl --location --request POST "${API_BASE}/1.0/nlp/default/saveDocumentPolicy/gg-dev-document-policy" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}" \
--data-raw '{
"metadata": {
"displayName": "gg-dev-document-policy",
"createdAt": "2019-05-15T11:06:17+00:00",
"updatedAt": "2019-09-03T12:58:52+00:00"
},
"label": "Article",
"textProperty": "content",
"getDocumentCardCypher": "UNWIND $batchedDocumentGrns AS articleGrn MATCH (article:Article {grn: articleGrn})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText) WITH article, at MATCH (at)-[:HAS_SENTIMENT]->(ats:AnnotatedTextSentiment) OPTIONAL MATCH (at)-[r:SUMMARY_SENTENCE]->(s:Sentence) WITH article, at, ats, r, s ORDER BY r.order WITH article, at, ats, rTrim(reduce(acc = '\'''\'', n IN COLLECT(s)| acc + n.sentence + '\'' '\'')) AS summary WITH article, at, ats, replace(summary, '\''\"'\'', '\'''\'') AS summary WITH article, at, ats, replace(summary, '\''"'\'', '\'''\'') AS summary WITH article, at, ats, replace(summary, '\''"'\'', '\'''\'') AS processedSummary MATCH (at)-[:HAS_TF]->(m:Mention) WITH article, at, ats, m, processedSummary OPTIONAL MATCH (m)<-[:MENTION_REPRESENTATIVE]-(x:KnowledgeGraphEntity) WITH article, at, ats, x, m, processedSummary OPTIONAL MATCH (rssSource:RSSSource {name: article.source}) WITH article, at, ats, x, m, processedSummary, rssSource OPTIONAL MATCH (article)<-[:HAS_TRANSLATION]-(nativeArticle:Article) RETURN article.grn AS grn, processedSummary AS summary, article.content AS fullText, article.pubDate as publishDate, article.title AS title, article.source AS source, rssSource.score AS trustScore, article.link AS sourceUrl, ats.sentiment AS sentiment, COLLECT(DISTINCT m.value) AS tags, '\''en'\'' AS language, COLLECT(x.grn) AS knowledgeGraphEntities, nativeArticle.content AS translatedFullText, nativeArticle.title AS translatedTitle, nativeArticle.grn AS nativeTextGrn",
"documentCardBatchVariable": "batchedDocumentGrns"
}'
Response
{
"metadata": {
"description": null,
"displayName": "gg-dev-document-policy",
"createdAt": "2019-05-15T11:06:17+00:00",
"updatedAt": "2021-01-25T15:44:01.551Z",
"versions": [
{
"metadata": {
"description": null,
"displayName": "gg-dev-document-policy",
"createdAt": "2019-05-15T11:06:17+00:00",
"updatedAt": "2021-01-25T15:13:43.357Z",
"versions": null
},
"label": "Article",
"textProperty": "content",
"getDocumentCardCypher": "UNWIND $batchedDocumentGrns AS articleGrn MATCH (article:Article {grn: articleGrn})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText) WITH article, at MATCH (at)-[:HAS_SENTIMENT]->(ats:AnnotatedTextSentiment) OPTIONAL MATCH (at)-[r:SUMMARY_SENTENCE]->(s:Sentence) WITH article, at, ats, r, s ORDER BY r.order WITH article, at, ats, rTrim(reduce(acc = '', n IN COLLECT(s)| acc + n.sentence + ' ')) AS summary WITH article, at, ats, replace(summary, '\"', '') AS summary WITH article, at, ats, replace(summary, '"', '') AS summary WITH article, at, ats, replace(summary, '"', '') AS processedSummary MATCH (at)-[:HAS_TF]->(m:Mention) WITH article, at, ats, m, processedSummary OPTIONAL MATCH (m)<-[:MENTION_REPRESENTATIVE]-(x:KnowledgeGraphEntity) WITH article, at, ats, x, m, processedSummary OPTIONAL MATCH (rssSource:RSSSource {name: article.source}) WITH article, at, ats, x, m, processedSummary, rssSource OPTIONAL MATCH (article)<-[:HAS_TRANSLATION]-(nativeArticle:Article) RETURN article.grn AS grn, processedSummary AS summary, article.content AS fullText, article.pubDate as publishDate, article.title AS title, article.source AS source, rssSource.score AS trustScore, article.link AS sourceUrl, ats.sentiment AS sentiment, COLLECT(DISTINCT m.value) AS tags, 'en' AS language, COLLECT(x.grn) AS knowledgeGraphEntities, nativeArticle.content AS translatedFullText, nativeArticle.title AS translatedTitle, nativeArticle.grn AS nativeTextGrn",
"documentCardBatchVariable": "batchedDocumentGrns"
}
]
},
"label": "Article",
"textProperty": "content",
"getDocumentCardCypher": "UNWIND $batchedDocumentGrns AS articleGrn MATCH (article:Article {grn: articleGrn})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText) WITH article, at MATCH (at)-[:HAS_SENTIMENT]->(ats:AnnotatedTextSentiment) OPTIONAL MATCH (at)-[r:SUMMARY_SENTENCE]->(s:Sentence) WITH article, at, ats, r, s ORDER BY r.order WITH article, at, ats, rTrim(reduce(acc = '', n IN COLLECT(s)| acc + n.sentence + ' ')) AS summary WITH article, at, ats, replace(summary, '\"', '') AS summary WITH article, at, ats, replace(summary, '"', '') AS summary WITH article, at, ats, replace(summary, '"', '') AS processedSummary MATCH (at)-[:HAS_TF]->(m:Mention) WITH article, at, ats, m, processedSummary OPTIONAL MATCH (m)<-[:MENTION_REPRESENTATIVE]-(x:KnowledgeGraphEntity) WITH article, at, ats, x, m, processedSummary OPTIONAL MATCH (rssSource:RSSSource {name: article.source}) WITH article, at, ats, x, m, processedSummary, rssSource OPTIONAL MATCH (article)<-[:HAS_TRANSLATION]-(nativeArticle:Article) RETURN article.grn AS grn, processedSummary AS summary, article.content AS fullText, article.pubDate as publishDate, article.title AS title, article.source AS source, rssSource.score AS trustScore, article.link AS sourceUrl, ats.sentiment AS sentiment, COLLECT(DISTINCT m.value) AS tags, 'en' AS language, COLLECT(x.grn) AS knowledgeGraphEntities, nativeArticle.content AS translatedFullText, nativeArticle.title AS translatedTitle, nativeArticle.grn AS nativeTextGrn",
"documentCardBatchVariable": "batchedDocumentGrns"
}
Document Cards
Get DocumentCard
Get the DocumentCard for a specific cluster and policy of an article.
Base URL: /1.0/nlp/{{clusterName}}/GetDocumentCard/{{documentPolicyName}}/{{nodeGrn}}
Method: GET
| Parameter | Description |
|---|---|
| clusterName string | The name of the cluster. |
| documentPolicyName string | The name of the document policy. |
| nodeGrn string | The grn of the annotatedText node. |
Request
curl --location --request GET "${API_BASE}/1.0/nlp/default/getDocumentCard/gg-dev-document-policy/grn:gg:article:RjsZUvOWHEHvGtZhQzHLk0FvXnF6Dop2XWLLluVsCdcY" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}"
Response
{
"grn": "grn:gg:article:RjsZUvOWHEHvGtZhQzHLk0FvXnF6Dop2XWLLluVsCdcY",
"publishDate": "2021-04-01T15:30:59Z",
"language": "en",
"imageUrl": null,
"title": "ONgDB - Graphs for the People!",
"summary": "Agility: Creating with Open Native Graph Database perfectly aligns with with lean interactive development practices, which lets your graph database evolve with the rest of the application and evolving business needs. Cache Sharding: ONgDB provides scale-out, in-memory read sharding to allow a high cache hit ratio where reads that are relevant to each instance in the cluster will warm the cache without needing to load the whole graph into memory. Key advantages Open Native Graph Database (ONgDB) offers for enterprises include: Referential Integrity: ONgDB is a reliable, scalable and high-performing native graph database that is suitable for enterprise use. For many use cases, ONgDB will provide orders of magnitude performance benefits compared to non-native graph, relational and NoSQL databases. ONgDB ensures that operations involving the modification of data happen within a transaction to guarantee consistent data.",
"fullText": "An open source, high performance, native graph store with everything you would expect from an enterprise-ready database, including high availability clustering, ACID transactions, and Geequel, an intuitive, pattern-centric graph query language. Developers use graph theory-based structures that we call nodes and relationships instead of rows and columns. For many use cases, ONgDB will provide orders of magnitude performance benefits compared to non-native graph, relational and NoSQL databases. Key advantages Open Native Graph Database (ONgDB) offers for enterprises include: Referential Integrity: ONgDB is a reliable, scalable and high-performing native graph database that is suitable for enterprise use. Applying proper ACID characteristics is a foundation of data reliability. ONgDB ensures that operations involving the modification of data happen within a transaction to guarantee consistent data. Quality Performance: When it comes to data relationship handling, ONgDB will vastly improve performance when dealing with network examination and depth based queries traversing out from a selected starting set of nodes within the native graph store. In comparison, relationship queries for a traditional database will come to a stop when the depth and complexity of the network around a single entity increases beyond a handful of JOIN operations. Flexibility: ONgDB provides data architect groups at businesses advantages in handling data changes because the schema and structure of a graph model is flexible when industries and applications change. Instead of modeling a domain in advance, when new data needs to be included in the graph structure the schema will update when it is written to the graph. Agility: Creating with Open Native Graph Database perfectly aligns with with lean interactive development practices, which lets your graph database evolve with the rest of the application and evolving business needs. ONgDB is enabling rapid development and agile maintenance. Cache Sharding: ONgDB provides scale-out, in-memory read sharding to allow a high cache hit ratio where reads that are relevant to each instance in the cluster will warm the cache without needing to load the whole graph into memory. There are many exciting features coming soon that will benefit the enterprise community. If you have a feature you'd like to see, let us know!\n",
"source": "graphfoundation",
"sourceUrl": "https://www.graphfoundation.org/ongdb/",
"sentiment": 0.6,
"trustScore": null,
"tags": [
"ONgDB",
"Geequel",
"Graph Database",
"NoSQL",
"[UNK] ONgDB",
"Open Native"
],
"knowledgeGraphEntities": [
"grn:gg:knowledgegraphentity:XuiGtMUgPeeh40p1evpbUFzE2DtJFcqlfa6ovsMrx1O6",
"grn:gg:knowledgegraphentity:47v26SDONDLsoJU9henwQT0HWdnqcAxslazu1ZsmQi7I",
"grn:gg:knowledgegraphentity:Zbn6BZzQM5hvwAWgdnL0QYLLbjsCQVWx8kboL40GCokv",
"grn:gg:knowledgegraphentity:PzgjyszBruGD9oBn4rXFF9d9Xy7UJjihxRdaSYH0uIdO"
],
"translatedFullText": null,
"translatedTitle": null,
"nativeTextGrn": null
}
Get Similar DocumentCards
Get similar DocumentCards related to an article of a specific cluster and policy.
Base URL: /1.0/nlp/{{clusterName}}/getSimilarDocumentCards/{{documentPolicyName}}/{{corpusGrn}}/{{nodeGrn}}
Method: GET
| Parameter | Description |
|---|---|
| clusterName string | The name of the cluster. |
| documentPolicyName string | The name of the document policy. |
| corpusGrn string | The grn of the corpus node. |
| nodeGrn string | The grn of the annotatedText node. |
Request
curl --location --request GET "${API_BASE}/1.0/nlp/default/getSimilarDocumentCards/gg-dev-document-policy/grn:gg:corpus:WBKz6mLFLWvegmSX7qNx5wKH5Nwiai3PFaFVT06iUbW6/grn:gg:article:EaD7RXiNYWuqqCrTdGDLjJPKlRUbVbmIErlyXrBAZhDE" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}"
Response
[
{
"grn": "grn:gg:article:EYTNI5YlNKgwYqpAUI84hhk7sUpgAEoOUWwUeNIRG4Qh",
"publishDate": "2021-04-01T15:30:59Z",
"language": "en",
"imageUrl": null,
"title": "Geequel-Graph Query Language for the People!",
"summary": "The intent with Geequel is to implement all of GQL and a big portion of openCypher® (openCypher® is a trademark of Neo4j, Inc.)\n Geequel is an implementation of openCypher®, the most widely adopted, fully-specified, and open query language for property graph databases. Geequel provides an intuitive way to work with ONgDB, a property graph, and is a great on-ramp to the Graph Query Language (GQL) standard being developed by ISO. Geequel is ONgDB's powerful Graph Query Language. Geequel looks a lot like ASCII art because it uses textual pattern representations to express nodes and relationships.",
"fullText": "Geequel is ONgDB's powerful Graph Query Language. It is a declarative, pattern matching language optimized for querying graph networks. Geequel is an implementation of openCypher®, the most widely adopted, fully-specified, and open query language for property graph databases. Geequel provides an intuitive way to work with ONgDB, a property graph, and is a great on-ramp to the Graph Query Language (GQL) standard being developed by ISO. Geequel is easy to learn and human-readable, making Geequel approachable, useful and unifying for business analysts, data scientists, software developers and operations professionals. The declarative nature of Geequel allows users to simply express the data they wish to retrieve while the underlying Geequel query runtime completes the task without burdening the user with Geequel implementation details. Geequel is one of the most powerful ways to effectively express graph database traversals for reading and writing data into ONgDB. Geequel makes it possible to direct ONgDB to do something like: "bring back my friends' friends right now" or "starting with this employee return their full reporting chain" in the form of several code lines. As such, Geequel queries and operations across all languages and integrations with ONgDB are able to query in a consistent manner. Geequel looks a lot like ASCII art because it uses textual pattern representations to express nodes and relationships. The nodes are surrounded with parenthesis which appear like circles and the relationships consist of dashes with square brackets. Here's an example: (graphs)-[:ARE]-(everywhere). Writing and representing depth based queries is one place where Geequel shines. To look at the friends of my friend's friends is as simple as "(me)-[:FRIEND*3]->(fofof). It is actually fun to create queries because the declarative nature of Geequel follows direct patterns and relationships without having to think about what needs joining together to aggregate the required data. In an RDBMS implementation with SQL, the queries mentioned above would involve a lot of code to write and perform poorly due to the number of joins. But with Geequel on ONgDB, it is possible to represent complex ideas with minimal code and optimized traversal performance at the same time. The intent with Geequel is to implement all of GQL and a big portion of openCypher® (openCypher® is a trademark of Neo4j, Inc.)\n",
"source": "graphfoundation",
"sourceUrl": "https://www.graphfoundation.org/geequel/",
"sentiment": 0.3888888888888889,
"trustScore": null,
"tags": [
"openCypher ®",
"Graph Query Language",
"ONgDB",
"Geequel",
"Inc .",
"[UNK] Graph Query Language",
"Neo4j",
"openCypher"
],
"knowledgeGraphEntities": [
"grn:gg:knowledgegraphentity:zcbhLThStPhhdBXJ4M7GqJ3dHkG4nntBZ0exJIRlUMXO",
"grn:gg:knowledgegraphentity:XuiGtMUgPeeh40p1evpbUFzE2DtJFcqlfa6ovsMrx1O6",
"grn:gg:knowledgegraphentity:47v26SDONDLsoJU9henwQT0HWdnqcAxslazu1ZsmQi7I",
"grn:gg:knowledgegraphentity:Ke1jZsWrpQtJrkOYFOiiqROGUE2ojT2JDnKDnWlI93aw",
"grn:gg:knowledgegraphentity:3QBudEEwHsa64U33eSOaNzeTuhMaAdjee5twLFgSZBaB",
"grn:gg:knowledgegraphentity:bZ75oM6rB2xeI9i8NdttvGzxg6aj0NEGHcTp3PBTQ9p0"
],
"translatedFullText": null,
"translatedTitle": null,
"nativeTextGrn": null
}
]
Get Recommended DocumentCards for User
Get recommended DocumentCards for a specific user.
Base URL: /1.0/nlp/{{clusterName}}/getRecommendedDocumentCards/{{documentPolicyName}}/{{userGrn}}
Method: GET
| Parameter | Description |
|---|---|
| clusterName string | The name of the cluster. |
| documentPolicyName string | The name of the document policy. |
| userGrn string | The grn of the user node. |
Request
curl --location --request GET "${API_BASE}/1.0/nlp/default/getRecommendedDocumentCards/gg-dev-document-policy/grn:gg:user:EeTO5wqULpuk1Xr8T8JQ2VcT5075cTvAWdmpjEDXnl9W" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}"
Response
[]
Get Most Recent DocumentCard Page
Get the most recent DocumentCard created in a corpus.
Base URL: /1.0/nlp/{{clusterName}}/getMostRecentDocumentCardsPage/{{documentPolicyName}}/{{corpusGrn}}/0/5
Method: GET
| Parameter | Description |
|---|---|
| clusterName string | The name of the cluster. |
| documentPolicyName string | The name of the document policy. |
| corpusGrn string | The grn of the corpus node. |
Request
curl --location --request GET "${API_BASE}/1.0/nlp/default/getMostRecentDocumentCardsPage/gg-dev-document-policy/grn:gg:corpus:67TMS82T8xCvyK2rAxkqxntGW9jISAeHVg4WZlQi6rnq/0/5" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}"
Response
[
{
"grn": "grn:gg:article:EYTNI5YlNKgwYqpAUI84hhk7sUpgAEoOUWwUeNIRG4Qh",
"publishDate": "2021-04-01T15:30:59Z",
"language": "en",
"imageUrl": null,
"title": "Geequel-Graph Query Language for the People!",
"summary": "The intent with Geequel is to implement all of GQL and a big portion of openCypher® (openCypher® is a trademark of Neo4j, Inc.)\n The intent with Geequel is to implement all of GQL and a big portion of openCypher® (openCypher® is a trademark of Neo4j, Inc.)\n Geequel is an implementation of openCypher®, the most widely adopted, fully-specified, and open query language for property graph databases. Geequel is an implementation of openCypher®, the most widely adopted, fully-specified, and open query language for property graph databases. Geequel provides an intuitive way to work with ONgDB, a property graph, and is a great on-ramp to the Graph Query Language (GQL) standard being developed by ISO. Geequel provides an intuitive way to work with ONgDB, a property graph, and is a great on-ramp to the Graph Query Language (GQL) standard being developed by ISO. Geequel is ONgDB's powerful Graph Query Language. Geequel is ONgDB's powerful Graph Query Language. Geequel looks a lot like ASCII art because it uses textual pattern representations to express nodes and relationships. Geequel looks a lot like ASCII art because it uses textual pattern representations to express nodes and relationships.",
"fullText": "Geequel is ONgDB's powerful Graph Query Language. It is a declarative, pattern matching language optimized for querying graph networks. Geequel is an implementation of openCypher®, the most widely adopted, fully-specified, and open query language for property graph databases. Geequel provides an intuitive way to work with ONgDB, a property graph, and is a great on-ramp to the Graph Query Language (GQL) standard being developed by ISO. Geequel is easy to learn and human-readable, making Geequel approachable, useful and unifying for business analysts, data scientists, software developers and operations professionals. The declarative nature of Geequel allows users to simply express the data they wish to retrieve while the underlying Geequel query runtime completes the task without burdening the user with Geequel implementation details. Geequel is one of the most powerful ways to effectively express graph database traversals for reading and writing data into ONgDB. Geequel makes it possible to direct ONgDB to do something like: "bring back my friends' friends right now" or "starting with this employee return their full reporting chain" in the form of several code lines. As such, Geequel queries and operations across all languages and integrations with ONgDB are able to query in a consistent manner. Geequel looks a lot like ASCII art because it uses textual pattern representations to express nodes and relationships. The nodes are surrounded with parenthesis which appear like circles and the relationships consist of dashes with square brackets. Here's an example: (graphs)-[:ARE]-(everywhere). Writing and representing depth based queries is one place where Geequel shines. To look at the friends of my friend's friends is as simple as "(me)-[:FRIEND*3]->(fofof). It is actually fun to create queries because the declarative nature of Geequel follows direct patterns and relationships without having to think about what needs joining together to aggregate the required data. In an RDBMS implementation with SQL, the queries mentioned above would involve a lot of code to write and perform poorly due to the number of joins. But with Geequel on ONgDB, it is possible to represent complex ideas with minimal code and optimized traversal performance at the same time. The intent with Geequel is to implement all of GQL and a big portion of openCypher® (openCypher® is a trademark of Neo4j, Inc.)\n",
"source": "graphfoundation",
"sourceUrl": "https://www.graphfoundation.org/geequel/",
"sentiment": 0.3888888888888889,
"trustScore": null,
"tags": [
"openCypher ®",
"Graph Query Language",
"ONgDB",
"Geequel",
"Inc .",
"[UNK] Graph Query Language",
"Neo4j",
"openCypher"
],
"knowledgeGraphEntities": [
"grn:gg:knowledgegraphentity:zcbhLThStPhhdBXJ4M7GqJ3dHkG4nntBZ0exJIRlUMXO",
"grn:gg:knowledgegraphentity:XuiGtMUgPeeh40p1evpbUFzE2DtJFcqlfa6ovsMrx1O6",
"grn:gg:knowledgegraphentity:47v26SDONDLsoJU9henwQT0HWdnqcAxslazu1ZsmQi7I",
"grn:gg:knowledgegraphentity:Ke1jZsWrpQtJrkOYFOiiqROGUE2ojT2JDnKDnWlI93aw",
"grn:gg:knowledgegraphentity:3QBudEEwHsa64U33eSOaNzeTuhMaAdjee5twLFgSZBaB",
"grn:gg:knowledgegraphentity:bZ75oM6rB2xeI9i8NdttvGzxg6aj0NEGHcTp3PBTQ9p0"
],
"translatedFullText": null,
"translatedTitle": null,
"nativeTextGrn": null
},
{
"grn": "grn:gg:article:RjsZUvOWHEHvGtZhQzHLk0FvXnF6Dop2XWLLluVsCdcY",
"publishDate": "2021-04-01T15:30:59Z",
"language": "en",
"imageUrl": null,
"title": "ONgDB - Graphs for the People!",
"summary": "Agility: Creating with Open Native Graph Database perfectly aligns with with lean interactive development practices, which lets your graph database evolve with the rest of the application and evolving business needs. Cache Sharding: ONgDB provides scale-out, in-memory read sharding to allow a high cache hit ratio where reads that are relevant to each instance in the cluster will warm the cache without needing to load the whole graph into memory. Key advantages Open Native Graph Database (ONgDB) offers for enterprises include: Referential Integrity: ONgDB is a reliable, scalable and high-performing native graph database that is suitable for enterprise use. For many use cases, ONgDB will provide orders of magnitude performance benefits compared to non-native graph, relational and NoSQL databases. ONgDB ensures that operations involving the modification of data happen within a transaction to guarantee consistent data.",
"fullText": "An open source, high performance, native graph store with everything you would expect from an enterprise-ready database, including high availability clustering, ACID transactions, and Geequel, an intuitive, pattern-centric graph query language. Developers use graph theory-based structures that we call nodes and relationships instead of rows and columns. For many use cases, ONgDB will provide orders of magnitude performance benefits compared to non-native graph, relational and NoSQL databases. Key advantages Open Native Graph Database (ONgDB) offers for enterprises include: Referential Integrity: ONgDB is a reliable, scalable and high-performing native graph database that is suitable for enterprise use. Applying proper ACID characteristics is a foundation of data reliability. ONgDB ensures that operations involving the modification of data happen within a transaction to guarantee consistent data. Quality Performance: When it comes to data relationship handling, ONgDB will vastly improve performance when dealing with network examination and depth based queries traversing out from a selected starting set of nodes within the native graph store. In comparison, relationship queries for a traditional database will come to a stop when the depth and complexity of the network around a single entity increases beyond a handful of JOIN operations. Flexibility: ONgDB provides data architect groups at businesses advantages in handling data changes because the schema and structure of a graph model is flexible when industries and applications change. Instead of modeling a domain in advance, when new data needs to be included in the graph structure the schema will update when it is written to the graph. Agility: Creating with Open Native Graph Database perfectly aligns with with lean interactive development practices, which lets your graph database evolve with the rest of the application and evolving business needs. ONgDB is enabling rapid development and agile maintenance. Cache Sharding: ONgDB provides scale-out, in-memory read sharding to allow a high cache hit ratio where reads that are relevant to each instance in the cluster will warm the cache without needing to load the whole graph into memory. There are many exciting features coming soon that will benefit the enterprise community. If you have a feature you'd like to see, let us know!\n",
"source": "graphfoundation",
"sourceUrl": "https://www.graphfoundation.org/ongdb/",
"sentiment": 0.6,
"trustScore": null,
"tags": [
"ONgDB",
"Geequel",
"Graph Database",
"NoSQL",
"[UNK] ONgDB",
"Open Native"
],
"knowledgeGraphEntities": [
"grn:gg:knowledgegraphentity:XuiGtMUgPeeh40p1evpbUFzE2DtJFcqlfa6ovsMrx1O6",
"grn:gg:knowledgegraphentity:47v26SDONDLsoJU9henwQT0HWdnqcAxslazu1ZsmQi7I",
"grn:gg:knowledgegraphentity:Zbn6BZzQM5hvwAWgdnL0QYLLbjsCQVWx8kboL40GCokv",
"grn:gg:knowledgegraphentity:PzgjyszBruGD9oBn4rXFF9d9Xy7UJjihxRdaSYH0uIdO"
],
"translatedFullText": null,
"translatedTitle": null,
"nativeTextGrn": null
},
{
"grn": "grn:gg:article:EYTNI5YlNKgwYqpAUI84hhk7sUpgAEoOUWwUeNIRG4Qh",
"publishDate": "2021-04-01T15:30:59Z",
"language": "en",
"imageUrl": null,
"title": "Geequel-Graph Query Language for the People!",
"summary": "The intent with Geequel is to implement all of GQL and a big portion of openCypher® (openCypher® is a trademark of Neo4j, Inc.)\n The intent with Geequel is to implement all of GQL and a big portion of openCypher® (openCypher® is a trademark of Neo4j, Inc.)\n Geequel is an implementation of openCypher®, the most widely adopted, fully-specified, and open query language for property graph databases. Geequel is an implementation of openCypher®, the most widely adopted, fully-specified, and open query language for property graph databases. Geequel provides an intuitive way to work with ONgDB, a property graph, and is a great on-ramp to the Graph Query Language (GQL) standard being developed by ISO. Geequel provides an intuitive way to work with ONgDB, a property graph, and is a great on-ramp to the Graph Query Language (GQL) standard being developed by ISO. Geequel is ONgDB's powerful Graph Query Language. Geequel is ONgDB's powerful Graph Query Language. Geequel looks a lot like ASCII art because it uses textual pattern representations to express nodes and relationships. Geequel looks a lot like ASCII art because it uses textual pattern representations to express nodes and relationships.",
"fullText": "Geequel is ONgDB's powerful Graph Query Language. It is a declarative, pattern matching language optimized for querying graph networks. Geequel is an implementation of openCypher®, the most widely adopted, fully-specified, and open query language for property graph databases. Geequel provides an intuitive way to work with ONgDB, a property graph, and is a great on-ramp to the Graph Query Language (GQL) standard being developed by ISO. Geequel is easy to learn and human-readable, making Geequel approachable, useful and unifying for business analysts, data scientists, software developers and operations professionals. The declarative nature of Geequel allows users to simply express the data they wish to retrieve while the underlying Geequel query runtime completes the task without burdening the user with Geequel implementation details. Geequel is one of the most powerful ways to effectively express graph database traversals for reading and writing data into ONgDB. Geequel makes it possible to direct ONgDB to do something like: "bring back my friends' friends right now" or "starting with this employee return their full reporting chain" in the form of several code lines. As such, Geequel queries and operations across all languages and integrations with ONgDB are able to query in a consistent manner. Geequel looks a lot like ASCII art because it uses textual pattern representations to express nodes and relationships. The nodes are surrounded with parenthesis which appear like circles and the relationships consist of dashes with square brackets. Here's an example: (graphs)-[:ARE]-(everywhere). Writing and representing depth based queries is one place where Geequel shines. To look at the friends of my friend's friends is as simple as "(me)-[:FRIEND*3]->(fofof). It is actually fun to create queries because the declarative nature of Geequel follows direct patterns and relationships without having to think about what needs joining together to aggregate the required data. In an RDBMS implementation with SQL, the queries mentioned above would involve a lot of code to write and perform poorly due to the number of joins. But with Geequel on ONgDB, it is possible to represent complex ideas with minimal code and optimized traversal performance at the same time. The intent with Geequel is to implement all of GQL and a big portion of openCypher® (openCypher® is a trademark of Neo4j, Inc.)\n",
"source": "graphfoundation",
"sourceUrl": "https://www.graphfoundation.org/geequel/",
"sentiment": 0.3888888888888889,
"trustScore": null,
"tags": [
"openCypher ®",
"Graph Query Language",
"ONgDB",
"Geequel",
"Inc .",
"[UNK] Graph Query Language",
"Neo4j",
"openCypher"
],
"knowledgeGraphEntities": [
"grn:gg:knowledgegraphentity:zcbhLThStPhhdBXJ4M7GqJ3dHkG4nntBZ0exJIRlUMXO",
"grn:gg:knowledgegraphentity:XuiGtMUgPeeh40p1evpbUFzE2DtJFcqlfa6ovsMrx1O6",
"grn:gg:knowledgegraphentity:47v26SDONDLsoJU9henwQT0HWdnqcAxslazu1ZsmQi7I",
"grn:gg:knowledgegraphentity:Ke1jZsWrpQtJrkOYFOiiqROGUE2ojT2JDnKDnWlI93aw",
"grn:gg:knowledgegraphentity:3QBudEEwHsa64U33eSOaNzeTuhMaAdjee5twLFgSZBaB",
"grn:gg:knowledgegraphentity:bZ75oM6rB2xeI9i8NdttvGzxg6aj0NEGHcTp3PBTQ9p0"
],
"translatedFullText": null,
"translatedTitle": null,
"nativeTextGrn": null
}
]
Data Extraction Overview
Data extraction is an asynchronous process that takes in a generic node with a generic text property and produces a variety of natural language domain nodes from the provided text. Data extraction provides the domain nodes for all of GraphGrid NLP's other features.
BERT vs CoreNLP Backends
Data extraction relies on either a BERT or CoreNLP backend for processing. Depending on which is used a slightly different graph will be produced, for example CoreNLP may result in a Mention node of "President Donald Trump" while BERT may result in a Mention node of "Donald Trump". They will however always produce the same domain of nodes, so one can switch from one to another without consequence.
Interacting with the existing graph
GraphGrid NLP is capable of running all its services on an already created graph, without disrupting the original graph's structure.
To account for different underlying graphs, we've written GraphGrid NLP in such a way that data extraction can occur on a node with any label and any text property. For example, we could run data extraction on any of the following:
- An "Article" node with a "content" property.
- An "Article" node with a "text" property.
- A "Paper" node with a "text" property. Since these nodes are outside the GraphGrid NLP domain we refer to these nodes as "text" nodes.
The data extraction process creates a HAS_ANNOTATED_TEXT relationship between a text node and its corresponding AnnotatedText node.
The Phases of Data Extraction
Data extraction is performed over three phases: phase 0 (or preprocessing), phase 1 (base data extraction), and phase 2 (supplementary data extraction). Phase 0 concentrates on preprocessing the text, for example translating or cleaning it. Phase 1 concentrates on using BERT and CoreNLP as a backbone to extract information from the text, and writing that to the graph. Phase 2 concentrates on supplementing the base data extraction, like tf-idf scores, document similarity, and article summarization.
NLP Models
Upload Model
Upload a NLP model.
Base URL: /1.0/nlp/uploadModel
Method: POST
| Parameter | Description |
|---|---|
| packagedModel multipart/form-data | Model tar/gz file |
Request
curl --location --request POST "${API_BASE}/1.0/nlp/uploadModel" \
--header "Authorization: Bearer ${BEARER_TOKEN}" \
--form 'packagedModel=@"/absolute/path/20201222T054419-sentimentBinaryLstmModel.tar.gz"'
Response
{
"task": "SENTIMENT_ANALYSIS",
"modelName": "20201222T054419-sentimentBinaryLstmModel",
"trainingDate": "2020-12-22T05:43:45.000+0000",
"corpora": ["sst2"],
"languages": ["en"],
"modelAccuracy": 0.9520017,
"testSet": "",
"inputTensors": [
{
"name": "masking_input:0",
"shape": [1, 128, 768],
"outputValues": null
}
],
"outputTensors": [
{
"name": "dense_1/Sigmoid:0",
"shape": [1, 1],
"outputValues": ["negative", "positive"]
}
],
"requiredOpsFiles": ["_lstm_ops.so"],
"checksum": null
}
Load Model
Load a model.
Base URL: /1.0/nlp/loadModel/sentimentBinaryLstmModel
Method: GET
Request
curl --location --request GET "${API_BASE}/1.0/nlp/loadModel/sentimentBinaryLstmModel" \
--header "Authorization: Bearer ${BEARER_TOKEN}"
Response
200 OK
Get Model Policy
Get a model policy.
Base URL: /1.0/nlp/getModelPolicy/nerModel
Method: GET
Request
curl --location --request GET "${API_BASE}/1.0/nlp/getModelPolicy/nerModel" \
--header "Authorization: Bearer ${BEARER_TOKEN}"
Response
{
"task": "NAMED_ENTITY_RECOGNITION",
"modelName": "nerModel",
"trainingDate": "2021-01-08T19:02:00.000+0000",
"corpora": ["conll"],
"languages": ["en"],
"modelAccuracy": 0.9895629,
"testSet": "",
"inputTensors": [
{
"name": "masking_input:0",
"shape": [1, 128, 768],
"outputValues": null
}
],
"outputTensors": [
{
"name": "dense_1/truediv:0",
"shape": [1, 128, 9],
"outputValues": [
"O",
"B-PER",
"I-PER",
"B-ORG",
"I-ORG",
"B-LOC",
"I-LOC",
"B-MISC",
"I-MISC"
]
}
],
"requiredOpsFiles": ["_lstm_ops.so"],
"checksum": null
}
Get Available Models by Task
List available models by task.
Base URL: /1.0/nlp/availableModels/sentiment_analysis
Method: GET
Request
curl --location --request GET "${API_BASE}/1.0/nlp/availableModels/sentiment_analysis" \
--header "Authorization: Bearer ${BEARER_TOKEN}"
Response
[
{
"task": "SENTIMENT_ANALYSIS",
"modelName": "sentimentBinaryLstmModel",
"trainingDate": "2020-12-22T05:43:45.000+0000",
"corpora": ["sst2"],
"languages": ["en"],
"modelAccuracy": 0.9520017,
"testSet": ""
}
]
Get All Available Models
List all available models.
Base URL: /1.0/nlp/availableModels
Method: GET
Request
curl --location --request GET "${API_BASE}/1.0/nlp/availableModels" \
--header "Authorization: Bearer ${BEARER_TOKEN}"
Response
{
"COREFERENCE_RESOLUTION": [
{
"task": "COREFERENCE_RESOLUTION",
"modelName": "coreferenceResolutionModel",
"trainingDate": "2022-01-25T20:57:11.000+0000",
"corpora": ["gap", "wikicoref"],
"languages": ["en"],
"modelAccuracy": 0.8369980454444885,
"testSet": ""
}
],
"NAMED_ENTITY_RECOGNITION": [
{
"task": "NAMED_ENTITY_RECOGNITION",
"modelName": "namedEntityRecognitionModel",
"trainingDate": "2022-01-12T14:13:54.000+0000",
"corpora": ["conll", "wikigold", "emerging"],
"languages": ["en"],
"modelAccuracy": 0.9832593202590942,
"testSet": ""
}
],
"PART_OF_SPEECH_TAGGING": [
{
"task": "PART_OF_SPEECH_TAGGING",
"modelName": "partOfSpeechTaggingModel",
"trainingDate": "2022-01-17T13:52:52.000+0000",
"corpora": ["conll", "gmb"],
"languages": ["en"],
"modelAccuracy": 0.9802309274673462,
"testSet": ""
}
],
"RELATION_EXTRACTION": [
{
"task": "RELATION_EXTRACTION",
"modelName": "relationExtractionModel",
"trainingDate": "2022-08-09T20:16:18.000+0000",
"corpora": ["kbp37"],
"languages": ["en"],
"modelAccuracy": 0.7307642698287964,
"testSet": ""
}
],
"TRANSLATION": [
{
"task": "TRANSLATION",
"modelName": "translationModel",
"trainingDate": "2022-02-07T22:42:14.000+0000",
"corpora": ["opus100"],
"languages": [
"zh",
"ja",
"fr",
"es",
"ar",
"pt",
"de",
"ru",
"el",
"tr",
"ko"
],
"modelAccuracy": 10.794290330674913,
"testSet": ""
}
],
"HELPER": [
{
"task": "HELPER",
"modelName": "helperModel",
"trainingDate": null,
"corpora": null,
"languages": null,
"modelAccuracy": null,
"testSet": null
}
],
"SENTIMENT_ANALYSIS": [
{
"task": "SENTIMENT_ANALYSIS",
"modelName": "20231009T234236-sentimentAnalysisCategoricalModel",
"trainingDate": "2023-10-09T23:42:42.000+0000",
"corpora": ["sst1"],
"languages": ["en"],
"modelAccuracy": 0.9587162137031555,
"testSet": ""
},
{
"task": "SENTIMENT_ANALYSIS",
"modelName": "sentimentAnalysisBinaryModel",
"trainingDate": "2022-01-17T19:18:08.000+0000",
"corpora": ["sst2"],
"languages": ["en"],
"modelAccuracy": 0.934317409992218,
"testSet": ""
},
{
"task": "SENTIMENT_ANALYSIS",
"modelName": "sentimentAnalysisCategoricalModel",
"trainingDate": "2022-02-25T21:52:56.000+0000",
"corpora": ["sst1"],
"languages": ["en"],
"modelAccuracy": 0.6969588994979858,
"testSet": ""
}
],
"KEYPHRASE_EXTRACTION": [
{
"task": "KEYPHRASE_EXTRACTION",
"modelName": "keyphraseExtractionModel",
"trainingDate": "2022-01-17T18:44:34.000+0000",
"corpora": ["semeval2017"],
"languages": ["en"],
"modelAccuracy": 0.7601593136787415,
"testSet": ""
}
]
}
Data Sets
To train models for BERT features we rely on several publicly available datasets. Models trained off of publicly available datasets include:
- Sentiment
- NER tagging
- Relation Extraction
- Antecedent Scoring
- Translation
BERT
BERT is Google's Bidirectional Encoder Representations from Transformers which is a pretrained model that can be finely tuned for state-of-the-art performance on several NLP tasks. GraphGrid NLP uses models based on BERT for the following NLP tasks:
- NER tagging
- POS tagging
- Sentiment Analysis
- Relation Extraction (KBP)
- Antecedent Scoring and Coreference Resolution
- Keyphrase Extraction
NLP Tasks
GraphGrid's NLP module runs several NLP tasks. When running data extraction endpoints, all NLP tasks are run by default. For performance purposes, it
is possible to pass in a parameter, nlpTasks, in the request body of an extraction endpoint. The value(s) of this parameter specify which tasks to be
run. The tasks dependencies defined in the table below should be taken into account when using this optional parameter.
| NLP Task | Description | Dependencies |
|---|---|---|
| Named entity recognition (NER) | Information extraction based on a trained model that seeks to locate and tag named entities as mentions such as person names, organizations, locations, quantities, etc. | - |
| Part of speech tagging (POS) | A process based on a trained model that categorizes words in a text in correspondence with a particular part of speech, depending on the definition of the word and its context. | - |
| Coreference Resolution | A task based on a trained model that seeks to resolve all expressions that refer to the same entity in a text. | NER, POS |
| Relation extraction (RE) | A task based on a trained model that seeks to extract and identify semantic relationships between entities in a text. | NER |
| Sentiment analysis | Information extraction based on a trained model that seeks to identify the sentiment within a text. | - |
| TF-IDF | An algorithm that seeks to determine how important a word is to a document in a collection or corpus. | NER |
| Similarity | A clustering algorithm that uses TF-IDF values of mentions to find similarities within or between text(s). | TF-IDF |
| Summarization | An algorithm based task that determines the most representative sentence in a text based on TF-IDF values. | TF-IDF |
| Translation | A task based on a trained model that is responsible for taking a text written in one langugage and translating it to another language. | - |
| Keyphrase tagging | A task based on a trained model that extracts words that represent the most relevant information contained in a text. | - |
nlpTasks Parameter for Extraction Endpoints
If specifiying NLP tasks, your data extraction endpoint may look like this:
curl --location --request POST "${API_BASE}/1.0/nlp/partialDataExtraction_bert" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}" \
--data-raw '{
"label": "Article",
"property": "content",
"processor": "bert",
"nlpTasks": "ner,pos,keyphrase,sentiment,re"
}'
The only NLP tasks that will be run from this endpoint are NER, POS, keyphrase tagging,sentiment analysis, and relation extraction.
Note that when using the nlpTasks parameter, some tasks should be in an abbreviated format like so:
| task | abbreviation |
|---|---|
| named entity recognition | ner |
| part of speech | pos |
| relation extraction | re |
| coreference resolution | coref |
| TF-IDF | tfidf |
| translation | - |
| similarity | - |
| summarization | - |
| keyphrase | - |
| sentiment | - |
If a task is not included that a specified NLP task depends on, an error will return with a message regarding the discrepency.
For example, if you were to run an extraction endpoint that specifies to run relation extraction (RE) but you left out named entity recognition (NER) an error would occur.
In the example response below, the error message states that extraction could not be run because RE requires NER.
{
"timestamp": "2022-05-18T18:19:14.347+0000",
"status": 500,
"error": "Internal Server Error",
"message": "re requires ner",
"path": "/1.0/nlp/partialDataExtraction_bert"
}
Performance notes regarding NLP tasks
The data extraction process takes a variable amount of time. Specifying which tasks to run may decrease the amount of time needed for processing, however the length and grammatical elements of the text to be processed may also affect the time.
Another factor may be your machine's CPU specifications. As an approximate example of extraction time, fully processing the text in the Article nodes
from the NLP tutorial takes about 15-25 minutes on a Core i9 machine.
It is generally not advised that NLP data extraction be reliant on a CPU environment at a production scale.
Translation & Multilingual Capabilities
Currently GraphGrid NLP only supports English for all of its features. Some languages such as Spanish or German are supported by some, but not all models.
A translation model is under development with the following target languages (in addition to English):
- Arabic
- Chinese
- French
- German
- Japanese
- Korean
- Portuguese
- Russian
- Spanish
These languages are also targets for native data extraction (without first translating to English).
Continuous Processing
The continuous processing triggers make use of custom apoc broker integrations. They work by picking up changes on the graph, doing some simple processing in Geequel, and then sending messages to a configured broker (RabbitMQ, SQS, or Kafka). Our modules listen to the broker(s), pulls the new messages, and then kicks off the java-based processing.
The endpoints for adding triggers to the graph return a 200 OK response if successful.
It is important to note that if CP is enabled, running the manual fullDataExtraction and partialDataExtraction endpoints may result
in double annotation. You should not have to use the manual data extraction endpoints if CP is set up, however it is important to be mindful of when CP is
enabled.
It is generally OK to run partialDataExtraction with CP running because it will only process text nodes that have not yet been processed. However, it is
possible for a node to be double-annotated if you have CP running, put a new article into the graph (which will trigger CP) and immediately run
partialDataExtraction without waiting for CP to finish.
Double-annotation will occur if CP is running and you hit the fullDataExtraction endpoint. This is because the manual fullDataExtraction endpoint processes
the text nodes regardless of whether they have been processed or not.
Always check that CP is disabled before manually requesting data extraction. To check if CP is enabled use this Geequel query in ONgDB:
CALL apoc.trigger.list
This will return a list of all the apoc triggers that are running. You should see the name of the continuousIndexing policy and a query that looks like this:
"WITH {createdNodes} AS createdNodes UNWIND createdNodes AS createdNode WITH createdNode WHERE createdNode:`Article` AND NOT createdNode:`Translation` WITH collect(createdNode.grn) AS batchedNodeIds WITH batchedNodeIds, ' CALL apoc.broker.send(\'rabbitmq\',{numTries: \'0\', transactionId: timestamp(), label: \'Article\', property: \'content\', corpusGrn: \'grn:gg:corpus:xjSR1yr4u08ERPxxcBKpgQpeZF1wvEbm3JYb3UeAkUcV\', processor: \'BERT\', idPartition: \''+apoc.convert.toString(batchedNodeIds)+'\' }, {config} ) YIELD connectionName AS `_connectionName`, message AS `_message`, configuration AS `_configuration` RETURN 1' AS brokerCall CALL apoc.cypher.doIt(' WITH {brokerCall} AS brokerCall, {batchedNodeIds} AS batchedNodeIds, {config} AS config CALL apoc.do.when(coalesce(size(batchedNodeIds) > 0, false), brokerCall, \'\', {brokerCall: {brokerCall}, batchedNodeIds:{batchedNodeIds}, config: {config}}) YIELD value RETURN value', {brokerCall: brokerCall, batchedNodeIds:batchedNodeIds, config: {config} } ) YIELD value AS brokerDoIt RETURN 1"
If you no longer want Continuous Processing enabled you can remove the trigger in ONgDB. To remove the processing trigger run:
CALL apoc.trigger.remove("<trigger_name>")
When used in conjunction with a continually ingesting source, this allows for a full pipeline from direct source to annotated text with full feature capabilities.
Below is a screenshot of the general continuous processing flow used in conjunction with RSS ingest.
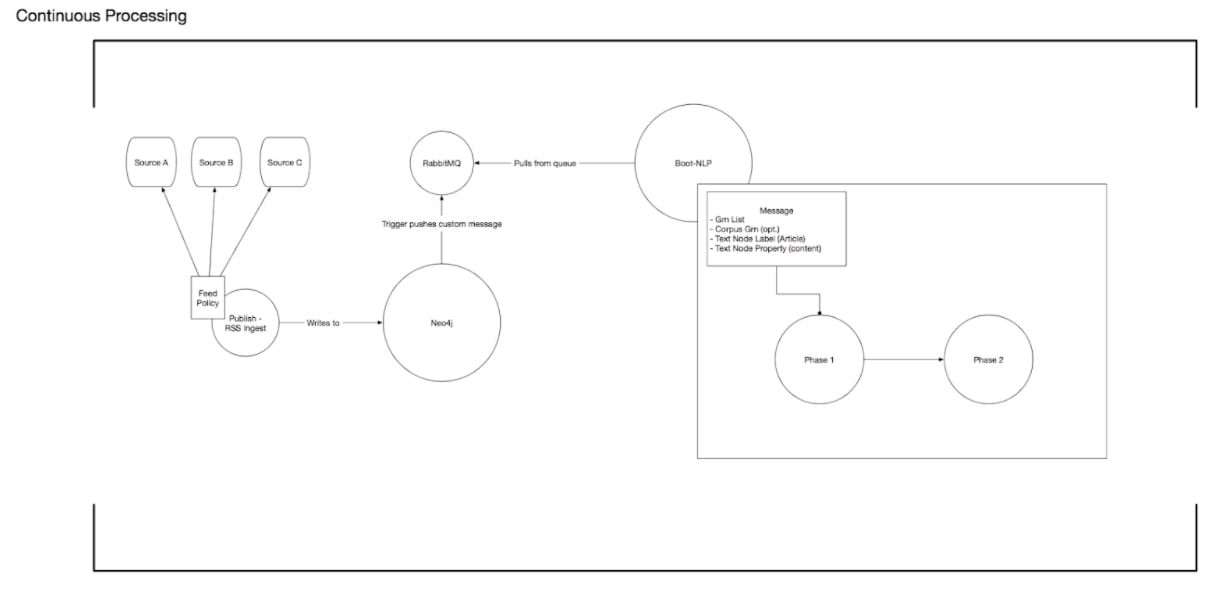
Continuous Processing Trigger
Enable continuous processing for text nodes.
Base URL: /1.0/nlp/{{clusterName}}/continuousProcessingTrigger/{{documentPolicyName}}
Method: POST
| Parameter | Description |
|---|---|
| clusterName string | The name of the cluster. |
| documentPolicyName string | The name of the document policy. |
Request
curl --location --request POST "${API_BASE}/1.0/nlp/default/continuousProcessingTrigger/gg-dev-document-policy" \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer ${BEARER_TOKEN}" \
--data-raw '{
"corpusGrn": "grn:gg:corpus:xjSR1yr4u08ERPxxcBKpgQpeZF1wvEbm3JYb3UeAkUcV",
"processor": "corenlp"
}'
Response
200 OK
Click here for or a full tutorial on how to set up RSS Ingest and continuous processing.