NLP Model Training
Introduction
NLP-model-training is a microservice responsible for building and training models within python via TensorFlow.
Project Structure
NLP-model-training is designed as a simple command line interface (CLI) in order to train natural language processing (NLP) models. As such it has the
commands prep, train, eval, cleanup, update_model_metadata_registry, and save.
The train command contains a complete end-to-end NLP model training pipeline with the tasks build_model, preprocess,
combine_datasets, cache, train, and model_policy.
CLI commands
prep
prep retrieves all the necessary dependencies in order to train a specified model and sets up the basic expected local training directory structure.
Parameters
| parameter | usage | required bool | default | choices | deprecation notice |
|---|---|---|---|---|---|
| datasets | JSON object with dataset info to train upon | True | None | see Airflow Documentation | N/A |
| model | Name of model to train | True | None | named_entity_recognition, part_of_speech_tagging, relation_extraction, coreference_resolution, sentiment_analysis_categorical, sentiment_analysis_binary, translation, keyphrase_extraction, test_model | N/A |
| gg_version | GraphGrid version to use | True | None | 1.4.0, 2.0.0, latest (only with local Airflow development) | N/A |
| request_body | Accepts a raw GraphGrid Airflow request body | False | None | see here | N/A |
| log_level | Flag to determine the level of logging | False | INFO | DEBUG, INFO, WARN, ERROR | N/A |
| dataset_bucket | name of the bucket which contains the training and evaluation datasets | True | None | graphgrid-datasets | N/A |
| bert_bucket | name of the bucket which contains a BERT model | True | None | graphgrid-nlp-models | Removed in 2.0.0 |
| endpoint_url | s3 or MinIO endpoint for dataset retrieval and saving resources out to | True | None | https://s3.us-west-2.amazonaws.com, http://Airflow-minio:9000 (only with local Airflow development) | N/A |
| remote_bert_model_path | path to the BERT model on remote cloud environment | True | None | resources/1.4/bertModel/ | Removed in 2.0.0 |
| remote_vocab_path | path to the vocab.txt on remote cloud environment for the associated BERT model on cloud storage service | True | None | resources/1.4/vocab.txt | Removed in 2.0.0 |
| top_level_path | Local path to cache training dependencies/resources/etc. NOTE: this path must not exist if running the prep task, otherwise it's expected to already exist. | True | None | N/A | N/A |
train
train a NLP model based on the specified parameters. This command includes a full end to end training pipeline which first preprocesses text from the raw
dataset/corpus format into a more standardized format (such as CoNLL). Following that transformation, data is processed further in preparation of being
embedded through BERT. This includes tokenization, truncation, and tracking of sentence metadata (word lengths, indices, etc.). Once data is embedded through
BERT, it undergoes further processing with post BERT embedding handlers. handlers vary heavily depending on the model, however, one common
operation is averaging subword tokens (e.g. averaging the embedding for the multi token word "ham ##burger"). See below for a simplified example processing
pipeline that a sample undergoes.
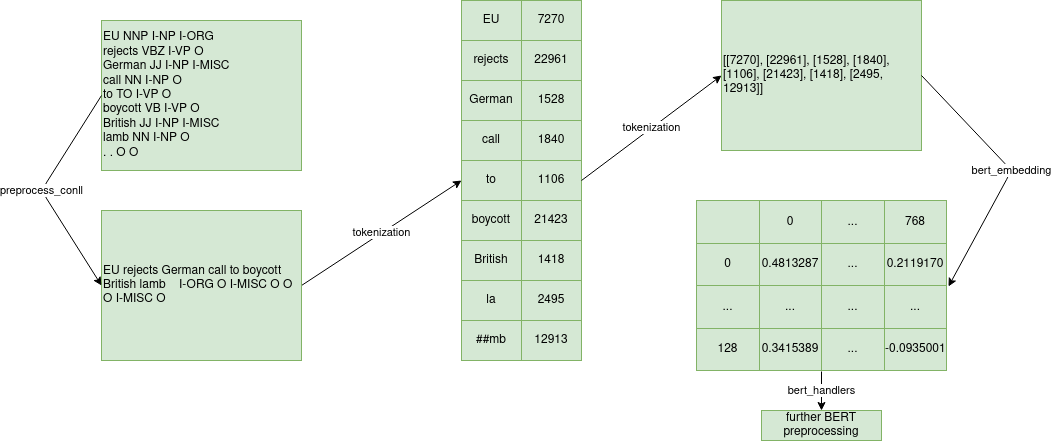
Once preprocessing through handlers is complete, data is cached for use during training. This allows models to only load the data that they are currently
using during training to avoid massive memory consumption. After the models are trained, they are saved and a model policy is created documenting various
characteristics of the previous training session (see here for information on model policies).
In addition to the training resources that are generated during training, a metadata.json file is generated at top_level_path/model_save/metadata.json
which contains relevant information to propagate to the evaluation task. This file is used as a resource and reference for the model-metadata-registry,
see here for more information regarding the model metadata registry.
Below is an example generated metadata.json file for a named_entity_recognition model.
{
"modelVersion": {
"modelName": "named_entity_recognition",
"trainingDataset": [
"conll"
],
"trainingAccuracy": 0.989,
"trainingLoss": 0.007,
"evalAccuracy": null,
"evalLoss": null,
"properties": {
"languages": [
"en"
]
}
}
}
Parameters
| parameter | usage | required bool | default | choices | deprecation notice |
|---|---|---|---|---|---|
| datasets | JSON object with dataset info to train upon | True | None | see Airflow Documentation | N/A |
| model | Name of model to train | True | None | named_entity_recognition, part_of_speech_tagging, relation_extraction, coreference_resolution, sentiment_analysis_categorical, sentiment_analysis_binary, translation, keyphrase_extraction, test_model | N/A |
| retraining | boolean for whether model is being retrained | False | false | true, false | N/A |
| request_body | Accepts a raw GraphGrid Airflow request body | False | None | see here | N/A |
| log_level | Flag to determine the level of logging | False | INFO | DEBUG, INFO, WARN, ERROR | N/A |
| top_level_path | Local path to cache training dependencies/resources/etc. NOTE: this path must not exist if running the prep task, otherwise it's expected to already exist. | True | None | N/A | N/A |
eval
eval reloads a trained model into memory from top_level_path/model_save/ and evaluates the model's performance on the evaluation test set (if one
exists for the given model). Once that is complete, the metadata.json file from top_level_path/model_save/metadata.json is updated with the evaluation
results.
Parameters
| parameter | usage | required bool | default | choices | deprecation notice |
|---|---|---|---|---|---|
| datasets | JSON object with dataset info to train upon | True | None | see Airflow Documentation | N/A |
| model | Name of model to train | True | None | named_entity_recognition, part_of_speech_tagging, relation_extraction, coreference_resolution, sentiment_analysis_categorical, sentiment_analysis_binary, translation, keyphrase_extraction, test_model | N/A |
| top_level_path | Local path to cache training dependencies/resources/etc. NOTE: this path must not exist if running the prep task, otherwise it's expected to already exist. | True | None | N/A | N/A |
save
save saves the trained model, resources, and dependencies out to the cloud storage environment as specified by the endpoint_url parameter.
Parameters
| parameter | usage | required bool | default | choices | deprecation notice |
|---|---|---|---|---|---|
| model | Name of model to train | True | None | named_entity_recognition, part_of_speech_tagging, relation_extraction, coreference_resolution, sentiment_analysis_categorical, sentiment_analysis_binary, translation, keyphrase_extraction, test_model | N/A |
| gg_version | GraphGrid version to use | True | None | 1.4.0, 2.0.0, latest (only with local Airflow development) | N/A |
| request_body | Accepts a raw GraphGrid Airflow request body | False | None | see here | N/A |
| endpoint_url | s3 or MinIO endpoint for dataset retrieval and saving resources out to | True | None | https://s3.us-west-2.amazonaws.com, http://Airflow-minio:9000 (only with local Airflow development) | N/A |
| save_bucket | The name of the bucket to save the model and resources to. | True | None | graphgrid-nlp-models | N/A |
update_model_metadata_registry
update_model_metadata_registry updates the model metadata registry based on the history of the trained model, and the generated metadata.json file.
For more information about the model metadata registry, see here.
Parameters
| parameter | usage | required bool | default | choices | deprecation notice |
|---|---|---|---|---|---|
| model | Name of model to train | True | None | named_entity_recognition, part_of_speech_tagging, relation_extraction, coreference_resolution, sentiment_analysis_categorical, sentiment_analysis_binary, translation, keyphrase_extraction, test_model | N/A |
| gg_version | GraphGrid version to use | True | None | 1.4.0, 2.0.0, latest (only with local Airflow development) | N/A |
| endpoint_url | s3 or MinIO endpoint for dataset retrieval and saving resources out to | True | None | https://s3.us-west-2.amazonaws.com, http://Airflow-minio:9000 (only with local Airflow development) | N/A |
| save_bucket | The name of the bucket to save the model and resources to. | True | None | graphgrid-nlp-models | N/A |
| top_level_path | Local path to cache training dependencies/resources/etc. NOTE: this path must not exist if running the prep task, otherwise it's expected to already exist. | True | None | N/A | N/A |
cleanup
cleanup cleans up the local training directory and all the related resources.
Parameters
| parameter | usage | required bool | default | choices | deprecation notice |
|---|---|---|---|---|---|
| model | Name of model to train | True | None | named_entity_recognition, part_of_speech_tagging, relation_extraction, coreference_resolution, sentiment_analysis_categorical, sentiment_analysis_binary, translation, keyphrase_extraction, test_model | N/A |
| top_level_path | Local path to cache training dependencies/resources/etc. NOTE: this path must not exist if running the prep task, otherwise it's expected to already exist. | True | None | N/A | N/A |
Model Policies
Model policies are a means of documenting the basic characteristics of a trained GraphGrid NLP model. A model policy informs any downstream project/app/etc.
how to interact with the model. This is mostly seen through the inputTensors, outputTensors, and requiredOpsFiles fields.
Here is an example model policy produced from a named_entity_recognition training session.
{
"corpora": [
"conll"
],
"languages": [
"en"
],
"checksum": "R1FKcWbcfmTwYY3ILeMaEw==",
"modelName": "20210223T221627-nerModel",
"inputTensors": [
{
"name": "masking_input:0",
"shape": [
1,
128,
768
]
}
],
"task": "NAMED_ENTITY_RECOGNITION",
"testSet": "",
"outputTensors": [
{
"name": "dense_1/truediv:0",
"shape": [
1,
128,
9
],
"outputValues": [
"O",
"B-PER",
"I-PER",
"B-ORG",
"I-ORG",
"B-LOC",
"I-LOC",
"B-MISC",
"I-MISC"
]
}
],
"modelAccuracy": "0.98931605",
"trainingDate": "2021-02-23T22:15:58",
"requiredOpsFiles": [
"_lstm_ops.so"
]
}
Here is a table describing all the fields within a model policy.
| Field | Description | Type |
|---|---|---|
| corpora | List of all the corpora/datasets the model was trained on | List of strings |
| languages | The languages the model was trained on | List of strings |
| checksum | A checksum that nlp-model-training generates for downstream projects to verify after retrieval | String |
| modelName | name of the model | String |
| inputTensors | List of nested JSON objects documenting the name and shape of the input layer | List of nested JSON objects |
| task | boot-nlp related task name for the specified model | String |
| testSet | Unused/empty string | String |
| outputTensors | List of nested JSON objects documenting the name and shape of the output layer | List of nested JSON objects |
| modelAccuracy | The model accuracy during training | String |
| trainingDate | The date when the model was trained | String |
| requiredOpsFiles | The required Ops files in order to run the model | List of strings |
Model Metadata Registry
The model metadata registry is a resource geared towards tracking all the trained models via the NLP-model-training pipeline and Airflow. This file lives at
the top level of the bucket used for saving models (default com-graphgrid-nlp). The registry is responsible for which models are selected for packaging. As such,
the newly trained model is compared to all the other currently trained models to determine whether it should be labeled as the current default model for
packaging once training and evaluation is complete.
This file should never be altered manually.
Here is a truncated sample of the current GraphGrid model metadata registry which includes models for both the 1.4 and 2.0 platform versions.
{
"org": {
"default": {
"package": {
"1.4.0": {
"models": {
"part_of_speech_tagging": {
"modelVersion": "20210107T172128-posModel",
"location": "https://s3.us-west-2.amazonaws.com/graphgrid-nlp-models/1.4.0/20210107T172128-posModel.tar.gz"
},
...
"sentiment_binary_lstm": {
"modelVersion": "20201222T054419-sentimentBinaryLstmModel",
"location": "https://s3.us-west-2.amazonaws.com/graphgrid-nlp-models/1.4.0/20201222T054419-sentimentBinaryLstmModel.tar.gz"
}
}
},
"2.0.0": {
"models": {
"part_of_speech_tagging": {
"modelVersion": "20210521T215028-posModel",
"location": "https://s3.us-west-2.amazonaws.com/graphgrid-nlp-models/2.0.0/20210521T215028-posModel.tar.gz"
},
...
"sentiment_categorical_lstm": {
"modelVersion": "20210325T110728-sentimentCategoricalLstmModel",
"location": "https://s3.us-west-2.amazonaws.com/graphgrid-nlp-models/2.0.0/20210325T110728-sentimentCategoricalLstmModel.tar.gz"
}
}
}
},
"trainedModels": {
"part_of_speech_tagging": {
"20201218T150016-posModel": {
"modelName": "part_of_speech_tagging",
"trainingDataset": "conll",
"trainingAccuracy": 0.954,
"trainingLoss": 0.154,
"evalAccuracy": 0.931,
"evalLoss": 0.246,
"properties": {
"languages": [
"en"
]
},
"location": "https://s3.us-west-2.amazonaws.com/graphgrid-nlp-models/1.4.0/20201218T150016-posModel.tar.gz",
"timestamp": "2020-12-18T15:00:16",
"platformVersion": "1.4.0"
},
...
"20210719T203352-posModel": {
"modelName": "part_of_speech_tagging",
"trainingDataset": [
"conll"
],
"trainingAccuracy": 0.945,
"trainingLoss": 0.035,
"evalAccuracy": 0.918,
"evalLoss": 0.056,
"properties": {
"languages": [
"en"
]
},
"location": "https://s3.us-west-2.amazonaws.com/graphgrid-nlp-models/2.0.0/20210719T203352-posModel.tar.gz",
"timestamp": "2021-07-19T20:33:52",
"platformVersion": "2.0.0"
}
},
...
"sentiment_categorical_lstm": {
"20210325T110728-sentimentCategoricalLstmModel": {
"modelName": "sentiment_categorical_lstm",
"trainingDataset": [
"sst1"
],
"trainingAccuracy": 0.749,
"trainingLoss": 0.607,
"evalAccuracy": 0.487,
"evalLoss": 1.354,
"properties": {
"languages": [
"en"
]
},
"location": "https://s3.us-west-2.amazonaws.com/graphgrid-nlp-models/2.0.0/20210325T110728-sentimentCategoricalLstmModel.tar.gz",
"timestamp": "2021-03-25T11:07:28",
"platformVersion": "2.0.0"
}
}
}
}
}
}
Training pipeline tasks
As the name implies, the train CLI command is the heart of NLP-model-training as it is responsible for
running the complete NLP model training pipeline.
Some of the pipeline tasks are shared by multiple different models (e.g. BERT embedding), while some other
models require custom or unique steps (e.g. translation models). The pipeline_config module dictates
which exact pipeline steps each model performs.
build_model
build_model builds and compiles a GraphGrid NLP model. The following are all the possible trainable/buildable
models: named_entity_recognition, part_of_speech_tagging, relation_extraction, coreference_resolution, sentiment_analysis_categorical,
sentiment_analysis_binary, translation, keyphrase_extraction, test_model.
preprocess
preprocess processes a given corpus/dataset's raw samples and transforms them into a more standardized format.
There are currently 10 preprocessing modules, which follow a naming scheme of preprocess_MODEL_CORPUS, unless
the corpus is shared across different models in which case the model field is dropped.
combine_datasets
combine_datasets loads all preprocessed datasets into memory, concatenates them, and then shuffles them.
In training scenarios where only a single corpus is used for training, this step still occurs, but simply
shuffles the dataset as there are not multiple datasets to combine.
cache
cache transforms the preprocessed dataset and caches it inside the local training directory.
For all models other than translation, this includes embedding the samples through BERT.
train
train trains a given model with the cached training samples from the cache task. Once training
is complete, the model is saved within the top_level_path/model_save directory.
model_policy
model_policy generates a model policy for the newly trained NLP model. For information regarding
model policies see here.
Pipeline parameters
The NLP pipeline defines parameter dataclasses to ease interfaces across distinct model training pipeline steps.
For example, the module build_model_parameters defines the dataclass BuildModelParameters which includes
the fields model_name, retraining, and retraining_path. Each parameter dataclass allows for a single
and simple interface between pipeline steps which places the responsibility of individual parameter retrieval on downstream
pipeline tasks. For example, if two different models have distinct model building modules which require different
parameters, we can embed both within BuildModelParameters and have the distinct modules retrieve only the parameters
that they need. This then allows us to define our pipeline through lambda functions that take in the parameter
dataclasses.
In the following sections, we'll go through each individual parameter dataclass and list out the associated
parameters.
BuildModelParameters
| Field | Description | Type |
|---|---|---|
| model_name | The name of the model | String |
| retraining | Flag to determine whether a pretrained model exists locally | Boolean |
| retraining_path | Path to local pretrained model | String |
CacheParameters
| Field | Description | Type |
|---|---|---|
| model_name | The name of the model | String |
| cache_path | Path to cache training samples | String |
| outfile_path | Path to preprocessed samples file or directory | String |
CombineDatasetsParameters
| Field | Description | Type |
|---|---|---|
| datasets | Dictionary with each dataset being an entry with relevant information | Dictionary |
| outfile_path | Path to preprocessed samples file or directory | String |
ModelPolicyParameters
| Field | Description | Type |
|---|---|---|
| model | The trained model | [BaseModel, TranslationModel] |
| datasets | List of all the datasets the model was trained on | List |
| history | History object that contains training performance metrics | [tf.keras.callbacks.History, DummyHistory] |
| model_policy_path | Path to save the model policy | String |
| languages | List of all the languages the model was trained on | List |
PreprocessingParameters
| Field | Description | Type |
|---|---|---|
| infile_path | Path to load raw dataset/corpus | String |
| outfile_path | Path to save preprocessed samples file or directory | String |
| dataset | Name of the dataset or corpus to preprocess | String |
| is_pos | Flag to mark part-of-speech models | Boolean |
TrainingParameters
| Field | Description | Type |
|---|---|---|
| model | The trained model | [BaseModel, TranslationModel] |
| model_name | The name of the model | String |
| cache_path | Path to cache training samples | String |
| model_save_path | Path to save the model | String |
Data transformation specifications by model
All samples and data undergoes different types of transformations before being fed directly into our models. This section breaks down each model's transformations in sequential order and documents what occurs at each step.
named_entity_recognition
| Training pipeline step | Input shape | Input shape type | Output shape | Output shape type | Link |
|---|---|---|---|---|---|
preprocess_conll | (None,) | String | (None,) | List of strings | here |
| tokenization | (batch_size,) | Batch of strings | (batch_size, None, None) | tf.RaggedTensor | here |
| BERT | (batch_size, None, None) | tf.RaggedTensor | [(batch_size, 768), (batch_size, 128, 768)] | tf.Tensor | here |
conll_handler | (batch_size, 128, 768) | tf.Tensor | (batch_size, 128, 768) | tf.Tensor | here |
part_of_speech_tagging
These transformation steps are identical to those of named_entity_recognition.
relation_extraction
| Training pipeline step | Input shape | Input shape type | Output shape | Output shape type | Link |
|---|---|---|---|---|---|
preprocess_re_kbp37 | (None,) | String | (None,) | List of strings | here |
| tokenization | (batch_size,) | Batch of strings | (batch_size, None, None) | tf.RaggedTensor | here |
| BERT | (batch_size, None, None) | tf.RaggedTensor | [(batch_size, 768), (batch_size, 128, 768)] | tf.Tensor | here |
handle_re_processing | (batch_size, 128, 768) | tf.Tensor | (batch_size, 128, 808) | tf.Tensor | here |
Relation extraction handler
The relation extraction handler takes BERT embeddings as its input and calculates the distance between
the mentions and relative words within the sample, then embeds their positions.
This yields a tensor of shape (batch_size, 128, 808). Relation extraction iterates token-by-token
through the BERT embedding to calculate the distance between the token and the mentions. This yields
two distances for every word (the distance is 0 when analyzing the mentions themselves). These distances
are then passed through both sin and cos functions and expanded to a dimensionality of 20. As there
are two mentions and 20 corresponding position embeddings, this allows the final output shape to arrive at
(batch_size, 128, 768 + 20 + 20).
coreference_resolution
| Training pipeline step | Input shape | Input shape type | Output shape | Output shape type | Link |
|---|---|---|---|---|---|
preprocess_crr_gap, preprocess_crr_wikicoref | (None,) | String | (None,) | List of strings | here |
| tokenization | (batch_size,) | Batch of strings | (batch_size, None, None) | tf.RaggedTensor | here |
| BERT | (batch_size, None, None) | tf.RaggedTensor | [(batch_size, 768), (batch_size, 128, 768)] | tf.Tensor | here |
handle_crr_processing | (batch_size, 128, 768) | tf.Tensor | (batch_size, 13854) | tf.Tensor | here |
Coreference resolution handler
The coreference resolution handler takes BERT embeddings as its input and calculates relative positional
information about the sample and then creates a flattened tensor of all the information of shape
(batch_size, 13854). Which can be broken down in the following manner:
((768 * 9 + 1 + 9) * 2 + 1 + 9).
The initial 768 * 9 are the following values:
| Index | Description |
|---|---|
| 0 | The first corresponding token embedding for the mention |
| 1 | The last corresponding token embedding for the mention |
| 2 | The first token embedding before the mention (e.g. mention index - 1) |
| 3 | The second token embedding before the mention (e.g. mention index - 2) |
| 4 | The first token embedding after the mention (e.g. mention index + 1) |
| 5 | The second token embedding after the mention (e.g. mention index + 2) |
| 6 | The mean of the 5 tokens following the mention |
| 7 | The mean of the 5 tokens before the mention |
| 8 | The pooled output of the sample |
As each embedded token has a shape of 768 and there are 9 different values.
The next singular appended value is the length of the mention within the sample.
The following 9 flat values are the "bucketized", i.e. one-hot encoded, sequence length of the tensor with depth 9. Finally,
as coreference resolution is concerned with two different mentions, we repeat this same process for the second mention. Which
is how we arrive at a shape of (batch_size, 13854).
keyphrase_extraction
| Training pipeline step | Input shape | Input shape type | Output shape | Output shape type | Link |
|---|---|---|---|---|---|
preprocess_keyphrase_semeval2017 | (None,) | String | (None,) | List of strings | here |
| tokenization | (batch_size,) | Batch of strings | (batch_size, None, None) | tf.RaggedTensor | here |
| BERT | (batch_size, None, None) | tf.RaggedTensor | [(batch_size, 768), (batch_size, 128, 768)] | tf.Tensor | here |
handle_keyphrase_processing | (batch_size, 128, 768) | tf.Tensor | (batch_size, 128, 768) | tf.Tensor | here |
Keyphrase extraction handler
The keyphrase extraction handler takes BERT embeddings as its input and does not alter it in any way.
Therefore, its exact output is the same as the BERT embedding, i.e. a tensor of shape (batch_size, 128, 768)
sentiment_analysis_binary and sentiment_analysis_categorical
| Training pipeline step | Input shape | Input shape type | Output shape | Output shape type | Link |
|---|---|---|---|---|---|
preprocess_sentiment_sst | here | ||||
| tokenization | (batch_size,) | Batch of strings | (batch_size, None, None) | tf.RaggedTensor | here |
| BERT | (batch_size, None, None) | tf.RaggedTensor | [(batch_size, 768), (batch_size, 128, 768)] | tf.Tensor | here |
handle_sentiment_lstm_processing, handle_sentiment_cat_lstm_processing | (batch_size, 128, 768) | tf.Tensor | (batch_size, 128, 768) | tf.Tensor | here |
Sentiment analysis handler
The sentiment analysis handler takes BERT embeddings as its input and does not alter it in any way.
Therefore, its exact output is the same as the BERT embedding, i.e. a tensor of shape (batch_size, 128, 768)
Shared transformations
Various transformations within the pipeline are shared across different models. This section goes through each shared transformation.
Tokenization
Tokenization takes in preprocessed samples and transforms them into the expected BERT input shape. This means that
we first split sentences by whitespaces (as labels for specific tasks correspond words to labels), tokenize
them through tensorflow_text.BertTokenizer, extract relevant metadata about the sentence (word indices, lengths, etc.),
and then reshape the ragged tensor into the format that the helper function/model bert_pack_inputs expects.
The exact input is individual sentences in a simple string format. While the exact output is a ragged tensor with two nested rows, where row one defines the flat dimension of all the words in the sentence, and row two defines tensor sub-dimensions for sub tokens (e.g. indices where single words are comprised of multiple sub-tokens).
BERT embedding
BERT embedding takes tokenized sentences and processes them through BERT. This step is directly downstream from Tokenization, which means
its input is the ragged tensor output from that step. The exact output for this step depends on whether the model expects pooled outputs
(which can be thought of the entire culmination of the sentence), or sequence output (every token from the sentence). BERT defines a
maximum sequence length for sentences, where any sentences that exceed that length in their number of tokens is truncated to the
sequence length. For all of our models, the sequence length is defined as 128. Therefore, the exact output for this step
is a either a tensor of shape (batch_size, 768), or (batch_size, 128, 768), where the former shape is for pooled outputs
and the latter shape is for sequence outputs.
CoNLL handler
CoNLL handler is the post-BERT processing module that is shared for part_of_speech_tagging and named_entity_recognition models. As a handler, this
step is directly downstream from BERT embedding, meaning it takes the sequence output from that step as its input. This step takes the mean
of sub-tokens across the input batch, which aligns the number of inputs to the number of labels and allows for better model performance. This
means that rather than retaining a multi-token word such as ham ##burger, we can take the mean of the BERT embeddings for the corresponding
tokens ham and ##burger as they're the same word corresponding to the same label. The exact output of this step is
(batch_size, 128, 768), however, all sub tensors within the sequence past the last word/token have be replaced with zero tensors.
Dataset Formats per model
Most of the NLP models utilize distinct datasets which use different formats. Therefore this section outlines each model's dataset and their basic formats.
named_entity_recognition
Computation Natural Language Learning (CoNLL)
"CoNLL2003: each word has to be on a separate line, and there must be an empty line after each sentence. A line must contain at least 2 columns, the first one being the word itself, the last one being the named entity. It does not matter if there are extra columns that contain tags or chunks in between. Tags have to be given in the IOB format (it can be IOB1 or IOB2)."
General sample format
| Word string | POS-tag IOB string | Syntactic chunk tag IOB string | NER-tag IOB string |
|---|---|---|---|
| Japan | NNP | I-NP | I-LOC |
| 's | POS | B-NP | O |
| Hashimoto | NNP | I-NP | I-PER |
| leaves | VBZ | I-VP | O |
| Brazil | NNP | I-NP | I-LOC |
| for | IN | I-PP | O |
| Peru | NNP | I-NP | I-LOC |
| . | . | O | O |
Raw example sentence
Japan NNP I-NP I-LOC
's POS B-NP O
Hashimoto NNP I-NP I-PER
leaves VBZ I-VP O
Brazil NNP I-NP I-LOC
for IN I-PP O
Peru NNP I-NP I-LOC
. . O O
Links
Wikigold
"Wikigold uses the text of 149 articles from the May 22, 2008 dump of English Wikipedia. The articles were selected at random from all articles describing named entities, with a roughly equal proportion of article topics from each of the four CONLL-03 classes (LOC, MISC, ORG, PER)."
General sample format
| Word | Pos-tag |
|---|---|
| 010 | I-MISC |
| is | O |
| the | O |
| tenth | O |
| album | O |
| from | O |
| Japanese | I-MISC |
| Punk | O |
| Techno | O |
| band | O |
| The | I-ORG |
| Mad | I-ORG |
| Capsule | I-ORG |
| Markets | I-ORG |
| . | O |
Raw example sentence
010 I-MISC
is O
the O
tenth O
album O
from O
Japanese I-MISC
Punk O
Techno O
band O
The I-ORG
Mad I-ORG
Capsule I-ORG
Markets I-ORG
. O
Links
Emerging and Rare Entities
"This shared task (WNUT2017 Shared Task) focuses on identifying unusual, previously-unseen entities in the context of emerging discussions. Named entities form the basis of many modern approaches to other tasks (like event clustering and summarization), but recall on them is a real problem in noisy text - even among annotators. This drop tends to be due to novel entities and surface forms. Take for example the tweet "so.. kktny in 30 mins?!" - even human experts find the entity kktny hard to detect and resolve. The goal of this task is to provide a definition of emerging and of rare entities, and based on that, also datasets for detecting these entities."
General sample format
| Word | NER-tag |
|---|---|
| @paulwalk | O |
| It | O |
| 's | O |
| the | O |
| view | O |
| from | O |
| where | O |
| I | O |
| 'm | O |
| living | O |
| for | O |
| two | O |
| weeks | O |
| . | O |
| Empire | B-location |
| State | I-location |
| Building | I-location |
| = | O |
| ESB | B-location |
| . | O |
| Pretty | O |
| bad | O |
| storm | O |
| here | O |
| last | O |
| evening | O |
| . | O |
Raw example format
@paulwalk O
It O
's O
the O
view O
from O
where O
I O
'm O
living O
for O
two O
weeks O
. O
Empire B-location
State I-location
Building I-location
= O
ESB B-location
. O
Pretty O
bad O
storm O
here O
last O
evening O
. O
Links
part_of_speech_tagging
English CoNLL
Part_of_speech_tagging follows the same format as named_entity_recognition.
General sample format
This is the same as named_entity_recognition barring usage of the POS-tags column rather than NER-tags.
Raw example sentence
This is the same as named_entity_recognition.
Links
Groningen Meaning Bank
"The Groningen Meaning Bank (GMB) consists of public domain English texts with corresponding syntactic and semantic representations. The GMB is developed at the University of Groningen. A multi-lingual version of the GMB is the Parallel Meaning Bank. A thorough description of the GMB can be found in the Handbook of Linguistic Annotation."
General sample format
| Sentence # | Word | POS | Tag |
|---|---|---|---|
| Sentence: 1 | Thousands | NNS | O |
| of | IN | O | |
| demonstrators | NNS | O | |
| have | VBP | O | |
| marched | VBN | O | |
| through | IN | O | |
| London | NNP | B-geo | |
| to | TO | O | |
| protest | VB | O | |
| the | DT | O | |
| war | NN | O | |
| in | IN | O | |
| Iraq | NNP | B-geo | |
| and | CC | O | |
| demand | VB | O | |
| the | DT | O | |
| withdrawal | NN | O | |
| of | IN | O | |
| British | JJ | B-gpe | |
| troops | NNS | O | |
| from | IN | O | |
| that | DT | O | |
| country | NN | O | |
| . | . | O |
Raw example sentence
Sentence: 1,Thousands,NNS,O
,of,IN,O
,demonstrators,NNS,O
,have,VBP,O
,marched,VBN,O
,through,IN,O
,London,NNP,B-geo
,to,TO,O
,protest,VB,O
,the,DT,O
,war,NN,O
,in,IN,O
,Iraq,NNP,B-geo
,and,CC,O
,demand,VB,O
,the,DT,O
,withdrawal,NN,O
,of,IN,O
,British,JJ,B-gpe
,troops,NNS,O
,from,IN,O
,that,DT,O
,country,NN,O
,.,.,O
Links
relation_extraction
kbp37 (SemEval-2010 Task 8 and MIML-RE)
Within SemEeval-2010 Task 8, "there are 9 directional relations and an additional 'other' relation, resulting in 19 relation classes in total. Given a sentence and two target nominals, a prediction is counted as correct only when both the relation and its direction are correct. The performance is evaluated in terms of the F1 score defined by SemEval-2010 Task 8 (Hendrickx et al., 2009)." kbp37 is a modified combination of the datasets SemEval-2010 Task 8 and MIML-RE. kbp37 "contains 18 directional relations and an additional 'no_relation' relation, resulting in 37 relation classes."
General sample format
First line of a single sample contains the sentence number and associated text.
| Sentence number | Text |
|---|---|
| 0 | " \ |
The second line of a sample contains the relation for the sentence.
| Relation |
|---|
| per:employee_of(e1,e2) |
Raw example sentence
0 " <e1> Thom Yorke </e1> of <e2> Radiohead </e2> has included the + for many of his signature distortion sounds using a variety of guitars to achieve various tonal options . "
per:employee_of(e1,e2)
Links
- kbp37 files (github)
- kbp37 paper (github)
- SemEval-2010 Task 8: Multi-Way Classification of Semantic Relations Between Pairs of Nominals (aclweb.org)
keyphrase_extraction
SemEval-2017 Task 10
"A corpus for the task is built from ScienceDirect open access publications and is available freely for participants, without the need to sign a copyright agreement. It consists of 500 journal articles evenly distributed among the domains Computer Science, Material Sciences and Physics. Three types of documents are provided: plain text documents, brat .ann standoff documents, and XML documents. Plain text documents contain sampled paragraphs, .ann files contain annotations for those paragraphs and .xml documents come with the original full article text. The training data part of the corpus consists of 350 documents, 50 are kept for development and 100 for testing."
General sample format
Text files consist of sentences with bracketed numbers added after keyphrases. Therefore, the formatting is simply:
| Text |
|---|
| ...which limits the allowed power density in fusion reactors [1] and is a severe technical challenge in itself [2]... |
An annotation file is organized in the following manner:
| ID | Label | Start-offset | End-offset | Surface-form |
|---|---|---|---|---|
| T1 | Process | 107 | 122 | fusion reactors |
| ... | ... | ... | ... | ... |
| T15 | Task | 267 | 293 | severe technical challenge |
Raw example sentence
Power and particle exhaust are crucial for the viability of any future fusion power plant concept. Heat in fusion reactors must be extracted through a wall and cannot be exhausted volumetrically, which limits the allowed power density in fusion reactors [1] and is a severe technical challenge in itself [2]. In addition, structural material changes resulting from neutron irradiation cause degradation in the heat exhaust capabilities of existing designs [3] and static surfaces can suffer severely from erosion due to impinging plasma particles [4,5]. It is concluded that conventional concepts and materials for plasma facing components (PFCs) reach their limits in terms of material lifetime and power exhaust at approximately 20MW/m2, which is presumably dramatically reduced to <10MW/m2 due to neutron damage in a D-T reactor [6] or even only half that value [7].
with corresponding annotation file:
T1 Process 107 122 fusion reactors
T2 Process 238 253 fusion reactors
T3 Process 464 479 static surfaces
T4 Material 0 26 Power and particle exhaust
T5 Process 365 384 neutron irradiation
T6 Task 615 639 plasma facing components
T7 Task 641 645 PFCs
* Synonym-of T7 T6
T8 Material 820 831 D-T reactor
T9 Process 322 349 structural material changes
T10 Material 322 341 structural material
T11 Material 520 546 impinging plasma particles
T12 Material 800 807 neutron
T13 Process 800 814 neutron damage
T14 Material 71 89 fusion power plant
T15 Task 267 293 severe technical challenge
Links
OpenKP
"OpenKeyPhrase(OpenKP), [is] a large scale, open domain keyphrase extraction dataset. The dataset features 148,124 real world web documents along with a human annotation indicating the 1-3 most relevant keyphrases."
It consists of "~100,000 urls from the Bing Index to get a representative sample of true domain diversity. Additionally, we sampled ~40,000 urls from the MSMARCO QA corpus since it can be considered a representative sample of open domain web document search. Once the urls are selected they are provided to an expert judge who visits the website, explores its content and when they are done annotates 1-3 keyphrases in the document they believe to be most salient to the overall document."
General sample format
| url | text | VDOM | Keyphrases |
|---|---|---|---|
| .../star-trek-discovery-season-1.html | Star Trek Discovery Season 1 Director NA Actors Jason Isaacs... | [{\"Id\":0,\"text\":\"Star Trek Discovery Season 1\",\"feature\":[44.0,728.0,78.0,45.0,1.0,0.0,1.0,0.0,20.0,0.0,44.0,728.0,78.0,45.0,1.0,0.0,1.0,0.0,20.0,0.0],\"start_idx\":0,\"end_idx\":5},...,{\"Id\":0,\"text\":\"Play Movie\",\"feature\":[673.0,83.0,2085.0,31.0,0.0,0.0,0.0,0.0,12.0,0.0,667.0,95.0,2086.0,29.0,1.0,0.0,0.0,0.0,12.0,0.0],\"start_idx\":309,\"end_idx\":311}]" | [["Star", "Trek"], ["Jason", "Isaacs"], ["Doug", "Jones"]] |
Raw example sample
{"url": "http://.../star-trek-discovery-season-1.html", "text": "Star Trek Discovery Season 1 Director NA Actors Jason Isaacs Doug Jones Shazad Latif Sonequa MartinGreen Genres SciFi Country USA Release Year 2017 Duration NA Synopsis Ten years before Kirk Spock and the Enterprise the USS Discovery discovers new worlds and lifeforms as one Starfleet officer learns to understand all things alien YOU ARE WATCHING Star Trek Discovery Season 1 000 000 Loaded Progress The video keeps buffering Just pause it for 510 minutes then continue playing Share Star Trek Discovery Season 1 movie to your friends Share to support Putlocker 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Version 1 Server Mega Play Movie Version 2 Server TheVideo Link 1 Play Movie Version 3 Server TheVideo Link 2 Play Movie Version 4 Server TheVideo Link 3 Play Movie Version 5 Server TheVideo Link 4 Play Movie Version 6 Server NowVideo Play Movie Version 7 Server NovaMov Play Movie Version 8 Server VideoWeed Play Movie Version 9 Server MovShare Play Movie Version 10 Server CloudTime Play Movie Version 11 Server VShare Link 1 Play Movie Version 12 Server VShare Link 2 Play Movie Version 13 Server VShare Link 3 Play Movie Version 14 Server VShare Link 4 Play Movie Version 15 Other Link 1 Play Movie Version 16 Other Link 2 Play Movie Version 17 Other Link 3 Play Movie Version 18 Other Link 4 Play Movie Version 19 Other Link 5 Play Movie Version 20 Other Link 6 Play Movie Version 21 Other Link 7 Play Movie Version 22 Other Link 8 Play Movie Version 23 Other Link 9 Play Movie Version 24 Other Link 10 Play Movie Version 25 Other Link 11 Play Movie Version 26 Other Link 12 Play Movie Version 27 Other Link 13 Play Movie Version 28 Other Link 14 Play Movie Version 29 Other Link 15 Play Movie", "VDOM": "[{\"Id\":0,\"text\":\"Star Trek Discovery Season 1\",\"feature\":[44.0,728.0,78.0,45.0,1.0,0.0,1.0,0.0,20.0,0.0,44.0,728.0,78.0,45.0,1.0,0.0,1.0,0.0,20.0,0.0],\"start_idx\":0,\"end_idx\":5},...,{\"Id\":0,\"text\":\"Play Movie\",\"feature\":[673.0,83.0,2085.0,31.0,0.0,0.0,0.0,0.0,12.0,0.0,667.0,95.0,2086.0,29.0,1.0,0.0,0.0,0.0,12.0,0.0],\"start_idx\":309,\"end_idx\":311}]", "KeyPhrases": [["Star", "Trek"], ["Jason", "Isaacs"], ["Doug", "Jones"]]}
Links
translation
OPUS-100
"OPUS-100 is an English-centric, meaning that all training pairs include English on either the source or target side, multi-lingual corpus covering 100 languages. The OPUS collection is composed of multiple corpora, ranging from movie subtitles to GNOME documentation to the Bible. The dataset is not curated or balanced, instead opting for the simplest approach of downloading all corpora for each language pair and concatenating them."
General sample format
See OPUS Data Formats for an in depth explanation of the formatting.
However, "files are untokenized (raw format) and they may contain multiple sentences per line. They are aligned together to their corresponding sentence(s) in the other language. Empty alignments are excluded from the plain text files." Therefore, the basic format is simply:
| Text |
|---|
| ... |
| It also contributes to stability and détente in our part of the world. |
| There is wide popular support for this policy. |
| ... |
with an aligning text document for the target language:
| Text |
|---|
| ... |
| Elle contribue également à la stabilité et à la détente dans notre secteur du monde. |
| Cette politique recueille une large adhésion populaire. |
| ... |
Raw example sentence
"Plain text files are provided for each bitext in OPUS. The name follows the typical name conventions used in Moses, i.e. using file extensions that correspond to the language ID. For example, for the RF corpus the two files for English and French are called:"
RF.en-fr.en
RF.en-fr.fr
The contents of the English file looks like this:
Statement of Government Policy by the Prime Minister, Mr Ingvar Carlsson, at the Opening of the Swedish Parliament on Tuesday, 4 October, 1988.
Your Majesties, Your Royal Highnesses, Mr Speaker, Members of the Swedish Parliament.
Sweden's policy of neutrality is of decisive importance for our peace and independence.
It also contributes to stability and détente in our part of the world.
There is wide popular support for this policy.
It will be pursued with firmness and consistency.
...
And the corresponding French file looks like this:
Declaration de Politique Générale du Gouvernement présentée mardi 4 octobre 1988 devant le Riksdag par Monsieur Ingvar Carlsson, Premier Ministre.
Majestés, Altesses Royales, Monsieur le Président, Mesdames et Messieurs les députés!
La politique suédoise de neutralité revêt une importance capitale pour la paix et l' indépendance de notre pays.
Elle contribue également à la stabilité et à la détente dans notre secteur du monde.
Cette politique recueille une large adhésion populaire.
Elle sera poursuivie avec énergie et cohérence.
...
Links
sentiment_analysis_binary and sentiment_analysis_categorical
SST-1 and SST-2 (extends MR)
MR: Movie reviews with one sentence per review. Classification involves detecting positive/negative reviews (Pang and Lee, 2005).
SST-1: Stanford Sentiment Treebank - an extension of MR but with train/dev/test splits provided and fine-grained labels.
The labels take the form of very positive, positive, neutral, negative, and very negative.
Note that data is actually provided at the phrase-level and hence we train the model on both phrases and sentences but only score on sentences at test time.
Thus the training set is an order of magnitude larger than listed in the above table.
SST-2 Same as SST-1 but with neutral reviews removed and binary labels.
General sample format
Both datasets follow the same format but differ in the range of their sentiment labels.
| Sentiment | Text |
|---|---|
| 4 | victor rosa is leguizamo 's best movie work so far , a subtle and richly internalized performance |
Raw example sentence (SST-1)
4 victor rosa is leguizamo 's best movie work so far , a subtle and richly internalized performance
Raw example sentence (SST-2)
0 plotless collection of moronic stunts is by far the worst movie of the year .
Links
coreference_resolution (antecedentScoring)
GAP and WikiCoref
"GAP is a gender-balanced dataset containing 8,908 coreference-labeled pairs of (ambiguous pronoun, antecedent name). It's sampled from Wikipedia and released by Google AI Language for the evaluation of coreference resolution in practical applications." Wikicoref is "an English corpus annotated for anaphoric relations, where all documents are from the English version of Wikipedia." Wikicoref maintains the following directory structure:
Documents
Evaluation
Annotation
Output
Documents contains all the plain text samples for use during training.
Annotation is in MMAX Project format, and "the markables are stored within /docName/Markables/docName_coref_level.xml."
Evaluation "contains Conll-2011 Format" files for evaluation model accuracy.
Output contains three subdirectories: Key, Dcoref, and Scoref.
Key contains "WikiCoref in Table,Text Format".
Dcoref contains "the output of Dcoref in Table,Text,StandfordXML format".
Scoref contains "the output of Scoref in Table,Text,StandfordXML Format" respectively.
For more details about Wikicoref please refer to "WikiCoref: An English Coreference-annotated Corpus of Wikipedia Articles."
Formatted example sentence (GAP)
| ID | Text | Pronoun | Pronoun-offset | A | A-offset | A-coref | B | B-offset | B-coref | URL |
|---|---|---|---|---|---|---|---|---|---|---|
| development-111 | Alice Perrers is the protagonist of Emma Campion's novel, The King's Mistress. She appears in Anya Seton's novel, Katherine. | She | 79 | Alice Perrers | 0 | TRUE | Emma Campion | 36 | FALSE | http://en.wikipedia.org/wiki/Alice_Perrers |
Raw example sentence (GAP)
development-111 Alice Perrers is the protagonist of Emma Campion's novel, The King's Mistress. She appears in Anya Seton's novel, Katherine. She 79 Alice Perrers 0 TRUE Emma Campion 36 FALSE http://en.wikipedia.org/wiki/Alice_Perrers
Formatted example sentence (Wikicoref)
Any of the training files under the Documents directory are simply plain text files containing sentences. Therefore, the format is:
| Text |
|---|
| Anatole France was a French poet, journalist, and novelist. He was born in Paris, and died in Saint-Cyr-sur-Loire... |
Raw example sentence (Wikicoref)
Per the training file Documents/Anatole France:
Anatole France was a French poet, journalist, and novelist. He was born in Paris, and died in Saint-Cyr-sur-Loire. He was a successful novelist, with several best-sellers. Ironic and skeptical, he was considered in his day the ideal French man of letters...