Graph Schema and Queries for NLP Data Extraction
A feature of GraphGrid's NLP module is that once it processes a text it stores its results in a graph format. This section explains what gets created and stored in the graph when text data is processed by NLP, and provides examples of how to query that data.
How NLP data extraction data is stored
GraphGrid's NLP module runs the following tasks on text data during data extraction:
- Named entity recognition (NER)
- Part of speech tagging (POS)
- Coreference resolution
- Relation extraction (RE)
- Sentiment analysis
- Summarization
- Translation
- Keyphrase tagging
The results from these tasks are stored in a graph database format. Once extraction is complete, the processed text node will have a
relationship to an AnnotatedText node.
The diagram below shows a processed Article node connected to an AnnotatedText node by a relationship called HAS_ANNOTATED_TEXT.

The properties of your Article node may be different based on the custom data added to the graph.
Annotated Text Nodes
If we were to think of the schema of the stored NLP extraction data, the AnnotatedText node would be the root. Each processed node has its
own AnnotatedText node that all of its NLP task results are related to.
For example, the diagram below shows the simplified expansion of an AnnotatedText node.
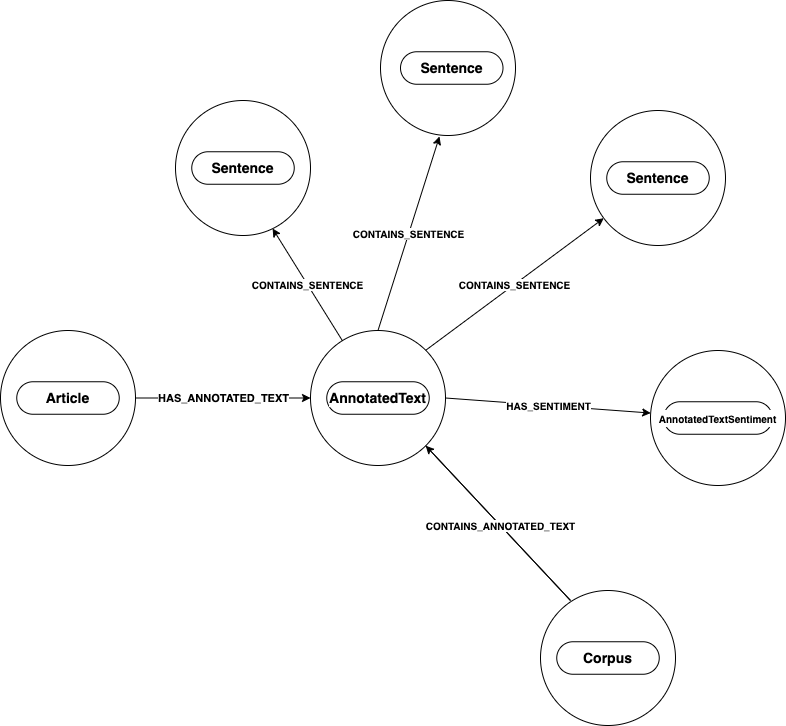
The Article node represents the users text data on the graph.
The node label Article is not required for NLP processing. Users of the NLP Module are free to choose another node
label to do text processing.
The important thing is that our text node (Article in this case) is processed by NLP and then connected to the AnnotatedText node.
Several nodes related to NLP tasks are connected to the AnnotatedText node.
The text node, (Article node), is connected to the AnnotatedText node by the relationship HAS_ANNOTATED_TEXT.
Each Article text node will have its own AnnotatedText node once it has been processed.

Properties of AnnotatedText nodes
Let's look at the properties of an AnnotatedText node and its HAS_ANNOTATED_TEXT created by data extraction.
AnnotatedText node
| Property | Description |
|---|---|
createdAt | The timestamp of when the node was created. |
grn | The grn of the node. |
lastSearchIndexedAt | The timestamp of when the node was last indexed by Search. |
text | The text that was processed by NLP. This property name is the same as the processed text node property (E.g. an Article node with the property text that holds the value of the textual data being processed will have an AnnotatedText node with the property text for that textual data). |
updatedAt | The timestamp of when the node was last updated. |
HAS_ANOTATED_TEXT relationship properties
| Property | Description |
|---|---|
createdAt | The timestamp of when the relationship was created. |
grn | The grn of the relationship. |
General guide for querying NLP extraction data
When attempting to access the NLP extraction data in the graph, it is important to be familiar with the schema created once extraction is complete. For instance if we want to only query text nodes that have specific mentions or keyphrases we might think that we can run a query like this:
MATCH (a:Article)-[:HAS_KEYPHRASE]->(k:Keyphrase) WHERE k.value = "GraphGrid" RETURN a
However this query will return no results because the relationships created by processing are not directly connected to the Article node. The
reason that the AnnotatedText node is generated is so that the NLP extraction data is isolated from the user's data. If we are basing our
query off of the processed text node to access information related to NLP data extraction, we need to match the processed text (Article)
node to its AnnotatedText node first.
We do this like so:
MATCH (a:Article)-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[:HAS_KEYPHRASE]->(k:Keyphrase) WHERE k.value = "GraphGrid" RETURN a
Every query that is based on the processed text node will start MATCH (a:Article)-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText).
Query 25 Article nodes that have AnnotatedText nodes:
MATCH (a:Article)-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText) RETURN a, at LIMIT 25
Query Article nodes that have AnnotatedText nodes that include "chewbacca" in the text:
MATCH (a:Article)-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText) WHERE toLower(at.text) INCLUDES "chewbacca" RETURN a
Corpus node
Every AnnotatedText node is connected to the Corpus node.
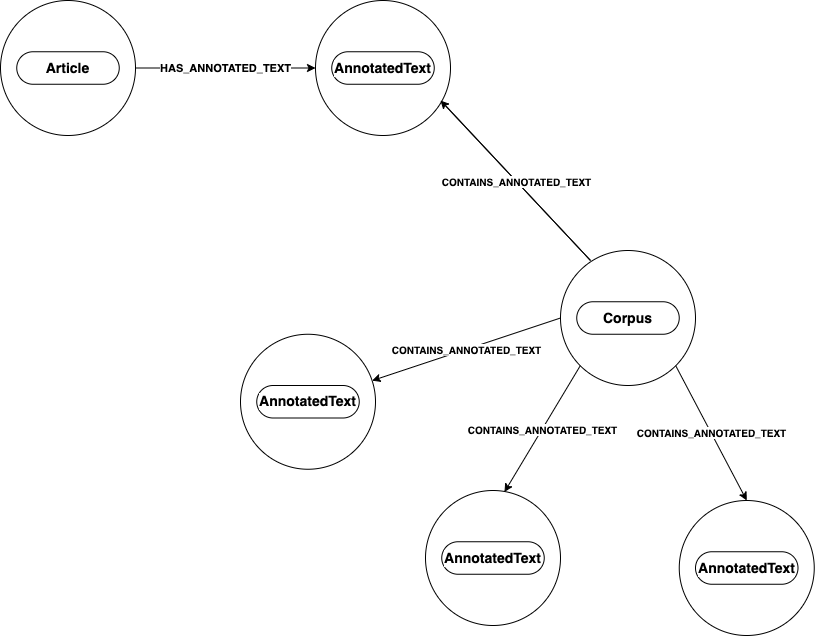
Like a regular corpus, it is a collection of texts but exists here in a graph format. We can think of the Corpus like a folder that contains
the data processing information.
The Corpus node is connected to every article in the graph by a relationship called CONTAINS_ANNOTATED_TEXT.
Corpus node properties
| Property | Description |
|---|---|
createdAt | The timestamp of when the node was created. |
grn | The grn of the node. |
lastSearchIndexedAt | The timestamp of when the node was last indexed by Search. |
name | The name of the node. |
updatedAt | The timestamp of when the node was last updated. |
CONTAINS_ANNOTATED_TEXT relationship properties
| Property | Description |
|---|---|
createdAt | The timestamp of when the relationship was created. |
grn | The grn of the relationship. |
Query the Corpus node
To query the Corpus node run:
MATCH (c:Corpus) RETURN c
NLP Metric Nodes
The NlpMetric node holds metrics for each processed text. Each annotatedText node is connected to an NlpMetric node by a HAS_METRIC relationship.

Properties of NlpMetric Nodes
| Property | Description |
|---|---|
createdAt | The timestamp of when the node was created. |
grn | The grn of the node. |
lastSearchIndexedAt | The timestamp of when the node was last indexed by Search. |
numberOfWords | The total number of words in the original text. |
totalTimeElapsed | The amount of time in seconds that it took to fully annotate the text. |
updatedAt | The timestamp of when the node was last updated. |
NLP Metric Node Queries
To query all NlpMetric nodes:
MATCH (n:NlpMetric) RETURN n
To query the NlpMetric node for a certain AnnotatedText:
MATCH (a:AnnotatedText)-[:HAS_METRIC]->(n:NlpMetric) RETURN n
Sentence Nodes
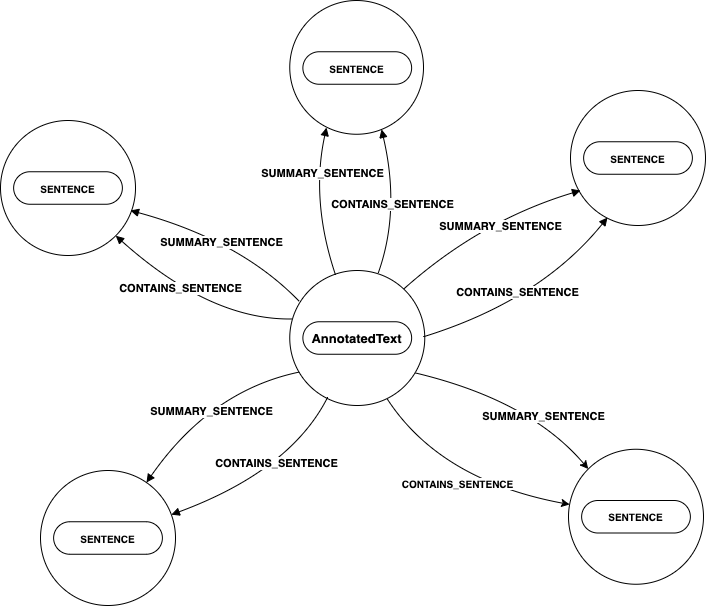
NLP works by extracting and processing a text sentence by sentence. This sentence data is stored on the graph as Sentence nodes.
In the diagram below, the AnnotatedText node has several outgoing relationships called CONTAINS_SENTENCE that connect to a Sentence node. There
is a Sentence node for every sentence in the processed text. Some Sentence nodes have more than one incoming relationship from the
AnnotatedText node, which we will go over as we continue.
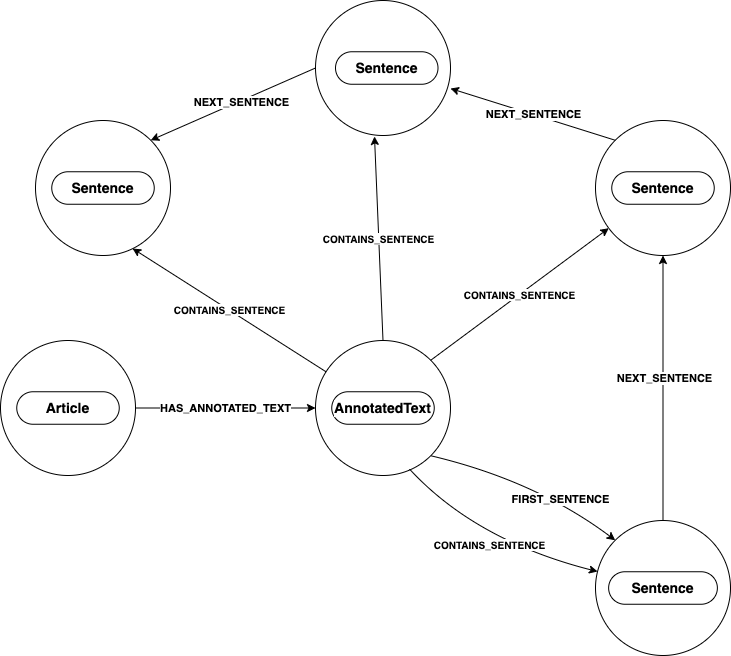
The AnnotatedText node in this diagram has two outgoing relationships, CONTAINS_SENTENCE and FIRST_SENTENCE, to a Sentence node.
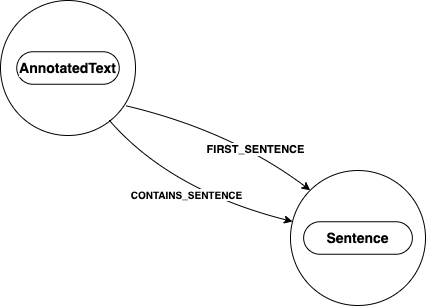
This Sentence node represents the first sentence of the processed text. Each sentence has a numeric sentenceNumber property starting with 0
and is assigned in ascending order until the end of the processed text.

NLP uses this property to determine the NEXT_SENTENCE relationship.
Properties of sentence nodes and their relationships
Sentence node
| Property | Description |
|---|---|
createdAt | The timestamp of when the node was created. |
grn | The grn of the node. |
lastSearchIndexedAt | The timestamp of when the node was last indexed by Search. |
sentence | A sentence of the processed text. |
sentenceNumber | The number assigned to the sentence in order by which it appears in the processed text. |
updatedAt | The timestamp of when the node was last updated. |
CONTAINS_SENTENCE, NEXT SENTENCE, FIRST_SENTENCE relationship properties
| Property | Description |
|---|---|
createdAt | The timestamp of when the relationship was created. |
grn | The grn of the relationship. |
updatedAt | The timestamp of when the node was last updated. |
Query Sentence Nodes
As mentioned under the general NLP data extraction querying section, to query all Sentence nodes based on the processed text, we have to
first match the processed text (Article) node to its AnnotatedText node. From there, our query can look for the
Sentence nodes.
If we run this query, we'll get all the Sentence nodes for a particular Article node:
MATCH (a:Article {grn: "grn:gg:article:JXqxrUXmNJq6uPw1tbUWH5Kw9iUfAciP952FPd1msrky"})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[:CONTAINS_SENTENCE]->(s:Sentence) RETURN s
This query matches the Article by its grn, then looks for an outgoing relationship HAS_ANNOTATED_TEXT connected to an AnnotatedText node
that has an outgoing relationship of CONTAINS_SENTENCE that connects to a Sentence node and returns that sentence.
If we want to query only the first sentence of a particular article we would run this:
MATCH (a:Article {grn: "grn:gg:article:JXqxrUXmNJq6uPw1tbUWH5Kw9iUfAciP952FPd1msrky"})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[:FIRST_SENTENCE]->(s:Sentence) RETURN s
This query follows a similar sequence as the one above, but instead of looking for the CONTAINS_SENTENCE relationship it's looking for
FIRST_SENTENCE. However, we're still matching our Article node to its AnnotatedText node first, then matching the AnnotatedText node to
the Sentence node.
We can also run a query that looks for and returns a sentence with a specific sentenceNumber property in a particular article:
MATCH (a:Article {grn: "grn:gg:article:JXqxrUXmNJq6uPw1tbUWH5Kw9iUfAciP952FPd1msrky"})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[:CONTAINS_SENTENCE]->(s:Sentence) WHERE s.sentenceNumber = 3 RETURN s
This query matches the Sentence node's property instead of its relationship.
Let's say we wanted to get more specific. If we want to query only sentences in this article that include "Chewbacca" we'd run this:
MATCH (a:Article {grn: "grn:gg:article:JXqxrUXmNJq6uPw1tbUWH5Kw9iUfAciP952FPd1msrky"})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[:CONTAINS_SENTENCE]->(s:Sentence) WHERE s.sentence CONTAINS "Chewbacca" RETURN s
Once again, the query matches our Article node by grn to our AnnotatedText node, and finds our Sentence node; but this time the query
looks for the sentence property and whether or not it contains "Chewbacca".
Summarization
NLP's summarization task calculates the most representative sentences in the processed text. This data is stored in the graph as a
relationship called SUMMARY_SENTENCE that points to those representative Sentence nodes. The SUMMARY_SENTENCE relationship is an
outgoing relationship from the AnnotatedText node to a Sentence node. Each SUMMARY_SENTENCE relationship has an order property. The
value of this property represents the order of the sentences for the predicted summary.
Summarization is the last task run during NLP data extraction processing. When a text is fully processed the last node created is called the
NlpProcessingSummary node.

The AnnotatedText node has a relationship called HAS_PROCESSING_SUMMARY that connects to the NlpProcessingNode. The node exists to
trigger Fuze policy changes that require NLP extraction data.
NlpProcessingSummary
| Property | Description |
|---|---|
createdAt | The timestamp of when the node was created. |
grn | The grn of the node. |
lastSearchIndexedAt | The timestamp of when the node was last indexed by Search. |
updatedAt | The timestamp of when the node was last updated. |
SUMMARY_SENTENCE relationship properties
| Property | Description |
|---|---|
createdAt | The timestamp of when the relationship was created. |
grn | The grn of the relationship. |
order | The order by which the sentence occurs in the overall predicted summary. |
updatedAt | The timestamp of when the node was last updated. |
Queries for Summarization
To return all of the summary sentences for a particular article run this query:
MATCH (a:Article {grn: "grn:gg:article:Oee1ccdOP8TYb0CC75mJ4j58t7bBqzG3hPvQb2IDtavP"})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[:SUMMARY_SENTENCE]->(s:Sentence) RETURN s
Use this query to return the summary sentences in order:
MATCH (a:Article {grn: "grn:gg:article:Oee1ccdOP8TYb0CC75mJ4j58t7bBqzG3hPvQb2IDtavP"})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[sum:SUMMARY_SENTENCE]->(s:Sentence) RETURN s ORDER by sum.order
Mention Nodes
A Mention node represents an entity (person, place, organization, or thing).
Results from the NER, POS and coreference resolution models are used to create and match existing Mention nodes on the graph.
Since different sentences may refer to the same entity we use a single Mention node as a representation of that entity.
This is captured through the relationship HAS_MENTION between a Mention and a Sentence.
The graph also tracks each occurrence of a mention as distinct information.
Any sentence that a mention occurs in creates a new MentionOccurrence node and attaches it to the sentence through
SENTENCE_MENTION_OCCURRENCE.
MentionOccurrence nodes represent individual usages of the Mention and store POS information about the usage.
Lastly, a MentionOccurrence is always connected back to its representative Mention through the MENTION_OCCURRENCE_MENTION relationship.
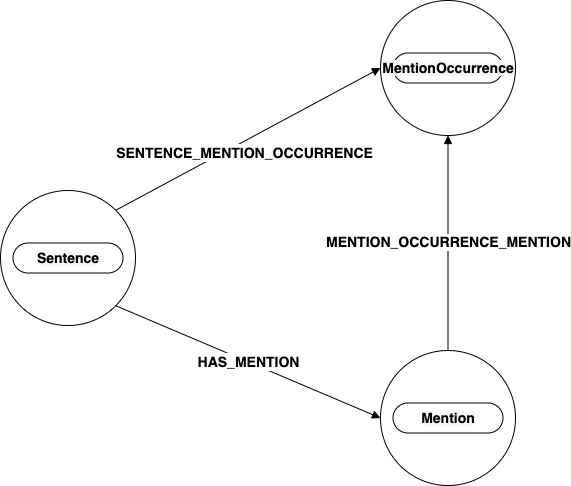
For example, this Sentence node has an outgoing relationship called HAS_MENTION that is connected to a Mention node. The
Sentence node has another outgoing relationship called SENTENCE_MENTION_OCCURRENCE that is connected to a MentionOccurrence node.
The MentionOccurrence node has an incoming relationship called MENTION_OCCURRENCE_MENTION that comes from the Mention node.
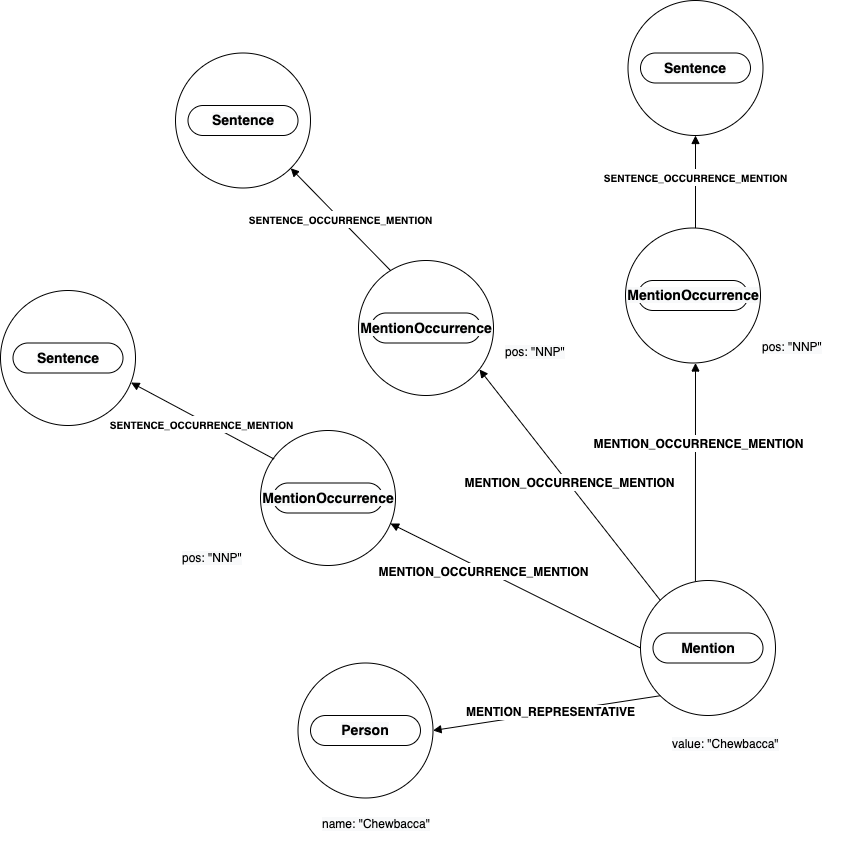
In the diagram above we see that there are 3 Sentence nodes that are each connected to one MentionOccurrence node. The MentionOccurrence
nodes have a POS property value of "NNP" and are each connected to the same Mention node that has a property value of "Chewbacca". From this
we can interpret that NLP predicted that these 3 sentences mention "Chewbacca" as a singular, proper noun (NNP).
The Mention node also has an incoming relationship of MENTION_REPRESENTATIVE that is attached to a Person node with the property name
equal to "Chewbacca". This node is the result
of NER processing. NLP determined that the mention "Chewbacca" was a person, and therefore created a Person node that is representative
of the Mention node.
The node attached to the other end of the MENTION_REPRESENTATIVE can be labeled as a PERSON, LOCATION, ORGANIZATION, or MISCELLANEOUS node. Some
mentions may have a combination of, or all three labels depending on NLP's computation and the context that the mention is used in.
Properties of Mention nodes
Mention node
| Property | Description |
|---|---|
createdAt | The timestamp of when the node was created. |
grn | The grn of the node. |
langauge | The langauge of the text. |
lastSearchIndexedAt | The timestamp of when the node was last indexed by Search. |
mentionId | The unique id of the mention, the value and the language property separated by an underscore ("_"). |
multiplicity | The multiplicity of the mention. |
ne | The named entity or entities of the mention (PERSON, LOCATION, ORGANIZATION, MISCELLANEOUS ). |
pos | The part of speech (POS) of the mention. |
updatedAt | The timestamp of when the node was last updated. |
value | The value of the mention. |
Mention Occurrence node
| Property | Description |
|---|---|
createdAt | The timestamp of when the node was created. |
grn | The grn of the node. |
langauge | The langauge of the text. |
lastSearchIndexedAt | The timestamp of when the node was last indexed by Search. |
pos | The part of speech (POS) of the mention. |
updatedAt | The timestamp of when the node was last updated. |
value | The value of the mention. |
HAS_MENTION, SENTENCE_MENTION_OCCURRENCE, MENTION_OCCURRENCE_MENTION, MENTION_OCCURRENCE_REPRESENTATIVE relationship properties
| Property | Description |
|---|---|
createdAt | The timestamp of when the relationship was created. |
grn | The grn of the relationship. |
order | The order by which the sentence occurs in the overall predicted summary. |
updatedAt | The timestamp of when the node was last updated. |
Querying Mention nodes
If we wanted to query all Mention nodes for a particular Article we would, once again, follow the sequence to get from Article to
Sentence, only this time we're traversing one more relationship, HAS_MENTION, in order to get to the Mention node.
MATCH (a:Article {grn: "grn:gg:article:JXqxrUXmNJq6uPw1tbUWH5Kw9iUfAciP952FPd1msrky"})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[:CONTAINS_SENTENCE]->(s:Sentence)-[:HAS_MENTION]->(m:Mention) RETURN m
This query matches the Article node by its grn, then finds it's AnnotatedText node in order to find its Sentence nodes. Finally, the
query looks at the Sentence node's outgoing relationship,HAS_MENTION, to find and return all Mention nodes.
If we wanted to get more specific, we can return only the Sentence nodes which have a connection to Mention nodes that have a value of
"Chewbacca" by running this query:
MATCH (a:Article {grn: "grn:gg:article:JXqxrUXmNJq6uPw1tbUWH5Kw9iUfAciP952FPd1msrky"})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[:CONTAINS_SENTENCE]->(s:Sentence)-[:HAS_MENTION]->(m:Mention) WHERE toLower(m.value) CONTAINS "chewbacca" RETURN s
To query all the people in a particular article:
MATCH (a:Article {grn: "grn:gg:article:JXqxrUXmNJq6uPw1tbUWH5Kw9iUfAciP952FPd1msrky"})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[:CONTAINS_SENTENCE]->(s:Sentence)-[:HAS_MENTION]->(m:Mention)<-[:MENTION_REPRESENTATIVE]-(p:Person) RETURN p
This query will return all nodes that have a label of Person. Some of these nodes may be tagged with several entities. For example, the Person node may have
a combination of, if not all the NER tags PERSON, LOCATION, ORGANIZATION, and/or MISCELLANEOUS. If you want to query nodes that are purely tagged
PERSON nodes run this:
MATCH (a:Article {grn: "grn:gg:article:JXqxrUXmNJq6uPw1tbUWH5Kw9iUfAciP952FPd1msrky"})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[:CONTAINS_SENTENCE]->(s:Sentence)-[:HAS_MENTION]->(m:Mention)<-[:MENTION_REPRESENTATIVE]-(n:Person) WHERE NOT n:Location AND NOT n:Organization RETURN n
Similarity Scoring
Similarities are scored based on Term Frequency-Inverse Document Frequency (TF-IDF) and Similarity Clustering methods.
Each Mention for a text document has its TF-IDF value calculated, and then highest valued Mentions used as a base to calculate how similar
two texts are.
Note that TF-IDF scores are calculated in the context of a Corpus, meaning the existing documents affect the TF-IDF values on mentions of a new
document.
Each Mention node has an incoming relationship called HAS_TF. This relationship is where the TF value part of TF-IDF is stored. These
scores are used
to calculate how similar two articles, or texts, are. If an article is similar to another, its AnnotatedText node will have a relationship to
its similar article's AnnotatedText node called HAS_SIMILAR.
Since IDF values change each time a new document is processed, IDF values are computed on the fly rather than stored in the graph.
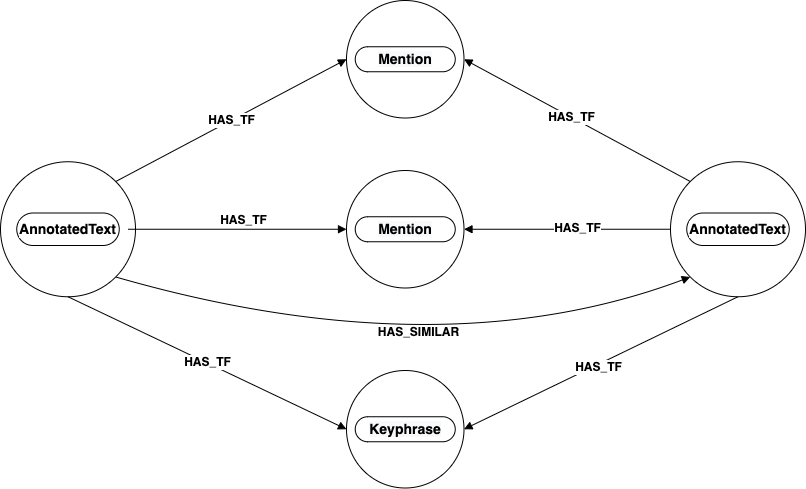
In the diagram above the two AnnotatedText nodes share two Mention nodes and a Keyphrase node through a relationship called HAS_TF. The
Mention and Keyphrase nodes' TF-IDF scores are used to calculate if two articles are similar.
Similar texts are organized within the graph itself.
Texts that are predicted to be similar, and belong to the same corpus, become part of a Similarity Cluster represented in the graph as a
SimilarityCluster node. TheAnnotatedText nodes belong to the SimilarityCluster node, as representened in
the graph by their outgoing BELONGS_TO_SIMILARITY_CLUSTER relationship.
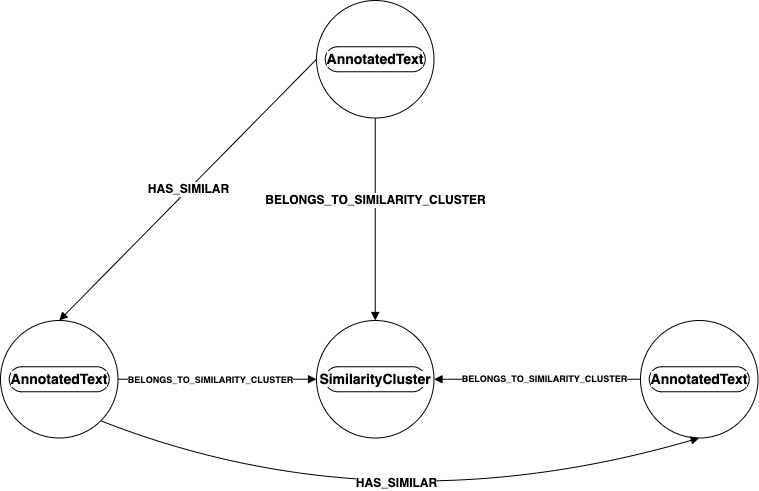
Properties for Similarity
SimilarityCluster node
| Property | Description |
|---|---|
createdAt | The timestamp of when the relationship was created. |
depth | The depth of the similarity cluster. |
grn | The grn of the relationship. |
lastSearchIndexedAt | The timestamp of when the node was last indexed by Search. |
updatedAt | The timestamp of when the node was last updated. |
HAS_TF
| Property | Description |
|---|---|
createdAt | The timestamp of when the relationship was created. |
grn | The grn of the relationship. |
tf | The term-frequency (TF) score of the mention or keyphrase. |
updatedAt | The timestamp of when the node was last updated. |
HAS_SIMILAR
| Property | Description |
|---|---|
corpusGrn | The grn of the Corpus that the AnnotatedText belongs to. |
createdAt | The timestamp of when the relationship was created. |
grn | The grn of the relationship. |
similarity | The similarity score of the two similar texts. |
updatedAt | The timestamp of when the node was last updated. |
BELONGS_TO_SIMILARITY_CLUSTER
| Property | Description |
|---|---|
createdAt | The timestamp of when the relationship was created. |
grn | The grn of the relationship. |
updatedAt | The timestamp of when the node was last updated. |
Queries for Similarity Scoring
Use this query to return the all the similar AnnotatedText nodes for a particular article:
MATCH (a:Article {grn: "grn:gg:article:ODSSvMKZzl4Nq2JqPwJtUBWW6izuxu43SMS5aQUY2Dce"})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[:HAS_SIMILAR]->(p:AnnotatedText) RETURN p
Remember, if we want to access information related to NLP data extraction, we always need to match the Article to its AnnotatedText node
first.
Our query finds the article's AnnotatedText node and then traverses the HAS_SIMILAR relationships to get the similar AnnotatedText nodes
and returns them.
Use this query to return the all the similar Article nodes for a particular article:
MATCH (a:Article {grn: "grn:gg:article:ODSSvMKZzl4Nq2JqPwJtUBWW6izuxu43SMS5aQUY2Dce"})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[:HAS_SIMILAR]->(p:AnnotatedText)<-[HAS_ANNOTATED_TEXT]-(x:Article) RETURN x
Just like the query above but with one added traversal, this query finds the similar AnnotatedText nodes, then looks at their
HAS_ANNOTATED_TEXT relationships to find their Article nodes.
To query all SimilarityCluster nodes run this:
MATCH (a:Article)-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[:BELONGS_TO_SIMILARITY_CLUSTER]->(sc:SimilarityCluster) RETURN a
Keyphrase
Keyphrase extaction data is stored as Keyphrase nodes on the graph. Keyphrase nodes are directly related to Sentence nodes through a
relationship called HAS_KEYPHRASE.
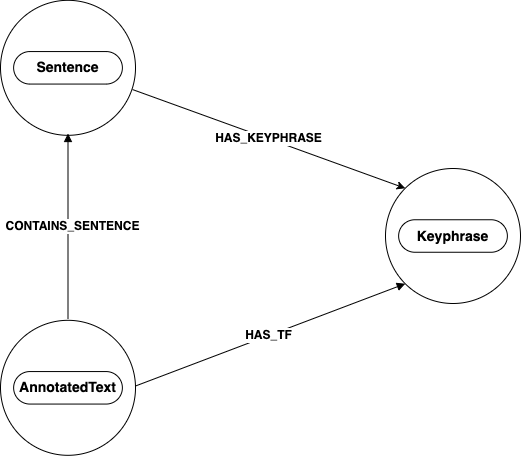
The Sentence node is connected to a Keyphrase node by a relationship HAS_KEYPHRASE. A Keyphrase node can also be directly
connected to an AnntatedText node by a HAS_TF relationship.
Properties for Keyphrase
Keyphrase node
| Property | Description |
|---|---|
createdAt | The timestamp of when the relationship was created. |
grn | The grn of the relationship. |
keyphraseId | The unique id of the keyphrase. |
lastSearchIndexedAt | The timestamp of when the node was last indexed by Search. |
updatedAt | The timestamp of when the node was last updated. |
value | The value of the keyphrase. |
HAS_KEYPHRASE relationship properties
| Property | Description |
|---|---|
createdAt | The timestamp of when the relationship was created. |
grn | The grn of the relationship. |
updatedAt | The timestamp of when the node was last updated. |
Queries for Keyphrase
To return the Keyphrase nodes that contain a particular phrase:
MATCH (a:Article {grn: "grn:gg:article:JXqxrUXmNJq6uPw1tbUWH5Kw9iUfAciP952FPd1msrky"})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[:CONTAINS_SENTENCE]->(s:Sentence)-[:HAS_KEYPHRASE]->(k:Keyphrase) RETURN k
To return the Keyphrase nodes that have a value that contain the a particular value:
MATCH (a:Article)-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[:CONTAINS_SENTENCE]->(s:Sentence)-[:HAS_KEYPHRASE]->(k:Keyphrase) WHERE toLower(k.value) contains "the force" RETURN k
Sentiment
The NLP sentiment task data is stored as two types of nodes, SentenceSentiment and AnnotatedTextSentiment.
The SentenceSentiment is the sentiment of a particular sentence, while the AnnotatedTextSentiment is the average of the SentenceSentiment
scores.
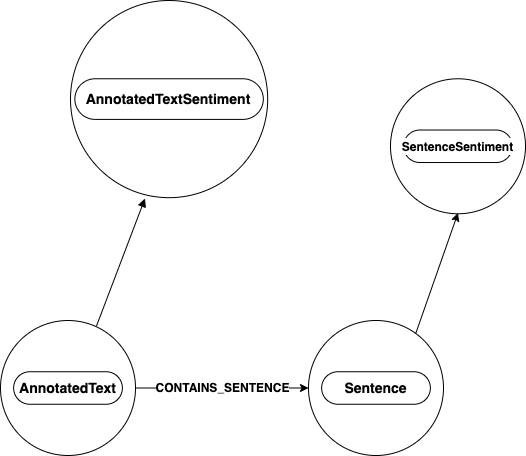
The Sentence node is connected to the SentenceSentiment node by a relationship called HAS_SENTIMENT. The AnnotatedText node is
connected to the AnnotatedTextSentiment node by a relationship also called HAS_SENTIMENT.
Properties for Sentiment
SentenceSentiment node
| Property | Description |
|---|---|
createdAt | The timestamp of when the relationship was created. |
grn | The grn of the relationship. |
lastSearchIndexedAt | The timestamp of when the node was last indexed by Search. |
sentiment | The sentiment score of the Sentence node |
sentimentType | The sentiment type. This can be either binary (positive/negative) or categorical. |
updatedAt | The timestamp of when the node was last updated. |
AnnotatedTextSentiment node
| Property | Description |
|---|---|
createdAt | The timestamp of when the relationship was created. |
grn | The grn of the relationship. |
lastSearchIndexedAt | The timestamp of when the node was last indexed by Search. |
sentiment | The sentiment score of the AnnotatedText node. |
updatedAt | The timestamp of when the node was last updated. |
HAS_SENTIMENT relationship properties
| Property | Description |
|---|---|
createdAt | The timestamp of when the relationship was created. |
grn | The grn of the relationship. |
updatedAt | The timestamp of when the node was last updated. |
Queries for Sentiment
This queries all SentenceSentiment nodes for a particular article:
MATCH (a:Article {grn: "grn:gg:article:JXqxrUXmNJq6uPw1tbUWH5Kw9iUfAciP952FPd1msrky"})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[:CONTAINS_SENTENCE]->(s:Sentence)-[:HAS_SENTIMENT]->(sent:SentenceSentiment) RETURN sent
This query returns sentences that contain "Doctor Strange" in them that have a negative sentiment:
MATCH (a:Article {grn: "grn:gg:article:JXqxrUXmNJq6uPw1tbUWH5Kw9iUfAciP952FPd1msrky"})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[:CONTAINS_SENTENCE]->(s:Sentence)-[:HAS_SENTIMENT]-(sent:SentenceSentiment) WHERE s.sentence CONTAINS "Doctor Strange" AND sent.sentimentType = "negative" RETURN s
To query the AnnotatedTextSentiment node run this:
MATCH (a:Article {grn: "grn:gg:article:JXqxrUXmNJq6uPw1tbUWH5Kw9iUfAciP952FPd1msrky"})-[:HAS_ANNOTATED_TEXT]->(at:AnnotatedText)-[:HAS_SENTIMENT]->(sent:AnnotatedTextSentiment) RETURN sent