Airflow
Platform 2.0
API Version N/A
Introduction
GraphGrid Airflow is responsible for orchestrating tasks defined through Directed Acyclic Graphs (DAGs). Per Airflow's official documentation, "A Task is the basic unit of execution in Airflow. Tasks are arranged into DAGs". One of the key types of Tasks are Operators, which are "a template for a predefined Task, that you can just define declaratively inside your DAG." For more conceptual information regarding Tasks, Operators, or DAGs see 1, 2, and 3 respectively.
DAGs
DAGs are the core foundational block that Airflow founds itself upon. For implementation specifics refer to the airflow docs here. Currently, Airflow wraps the NLP model training module's training pipeline as an executable DAG. The following section covers the implementation specifics for that DAG.
NLP Model Training DAG
The NLP model training DAG is made of the following tasks:
check_request_body- check the input request body/Configuration JSON (see here)create_unique_session_path- creates the DAG run specific volume to store and propagate training resourcesretrieve_resources- retrieve training resources (corpora, models, etc.) (see here)determine_cpu_or_gpu- determine whether the current training session is using a GPU or CPUgpu_training_sensor- sensor to determine whether all training sessions are in a valid state and runninggpu_preflight_configuration- blocking heuristic task to determine whether the current environment can support the current training sessiongpu_pool_setup- modify the GPU training pooltrain_model_gpu- train a model via GPU (see here)train_model_cpu- train a model via CPU (see here)save_model- save a model (see here)eval_model- evaluate a model's performance (see here)update_model_metadata_registry- update the model metadata registry (see here)cleanup- remove all generated and retrieved resourcesdelete_volume- delete the dynamically created volume for the current DAG runcheck_DAG_success- parse whether all tasks succeeded, otherwise fail.
GraphgridDockerOperator
The NLP model training DAG uses the GraphgridDockerOperator, which is an expanded and improved implementation
of Airflow's docker provider's DockerOperator. The GraphgridDockerOperator is a part of the airflow-provider-graphgrid package.
It has been improved to add additional configuration to the spawned containers
to allow for logging customization, GPU passthrough and support, and much more.
As the GraphgridDockerOperator extends the DockerOperator, please refer to its documentation here
for more information pertaining to base parameters.
New parameters specific to GraphgridDockerOperator:
labels(dict) - Labels to bind to the container (see here)gpu(bool) - Flag to allow GPU passthrough to allow for GPU accelerationinclude_credentials(bool) - Flag to include the requisite SDK credentialsgpu_label(bool) - Flag to label the container as using a GPUgpu_healthcheck(bool) - Flag to enable a GPU healthcheck to determine whentensorflowhas started
The current template fields are as follows:
commandenvironmentcontainer_nameimagemountsgpu
GraphgridMount
The GraphgridMount wraps the Python Docker SDK's docker.types.Mount to allow its fields to use Jinja templates and thus
dynamically named and mounted. The GraphgridMount is also a part of the airflow-provider-graphgrid package.
The current template fields are as follows:
source
Usage
Airflow is accessible at localhost:8081, which will prompt you to login.
Default username: airflow
Default password: airflow
If you have generated random credentials using the passwords generate GraphGrid CLI command
(./bin/graphgrid passwords generate), your new password can be found in ${GRAPHGRID_DATA}/env/airflow.env.
Following authentication, you will be greeted with the following home screen.
If you select the nlp_model_training DAG within the DAGs list, you will get the tree view of the DAG.
To kick off the DAG and begin the NLP model training pipeline, select the Trigger DAG w/ config
option under the play button UI element on the upper right side of the webpage.
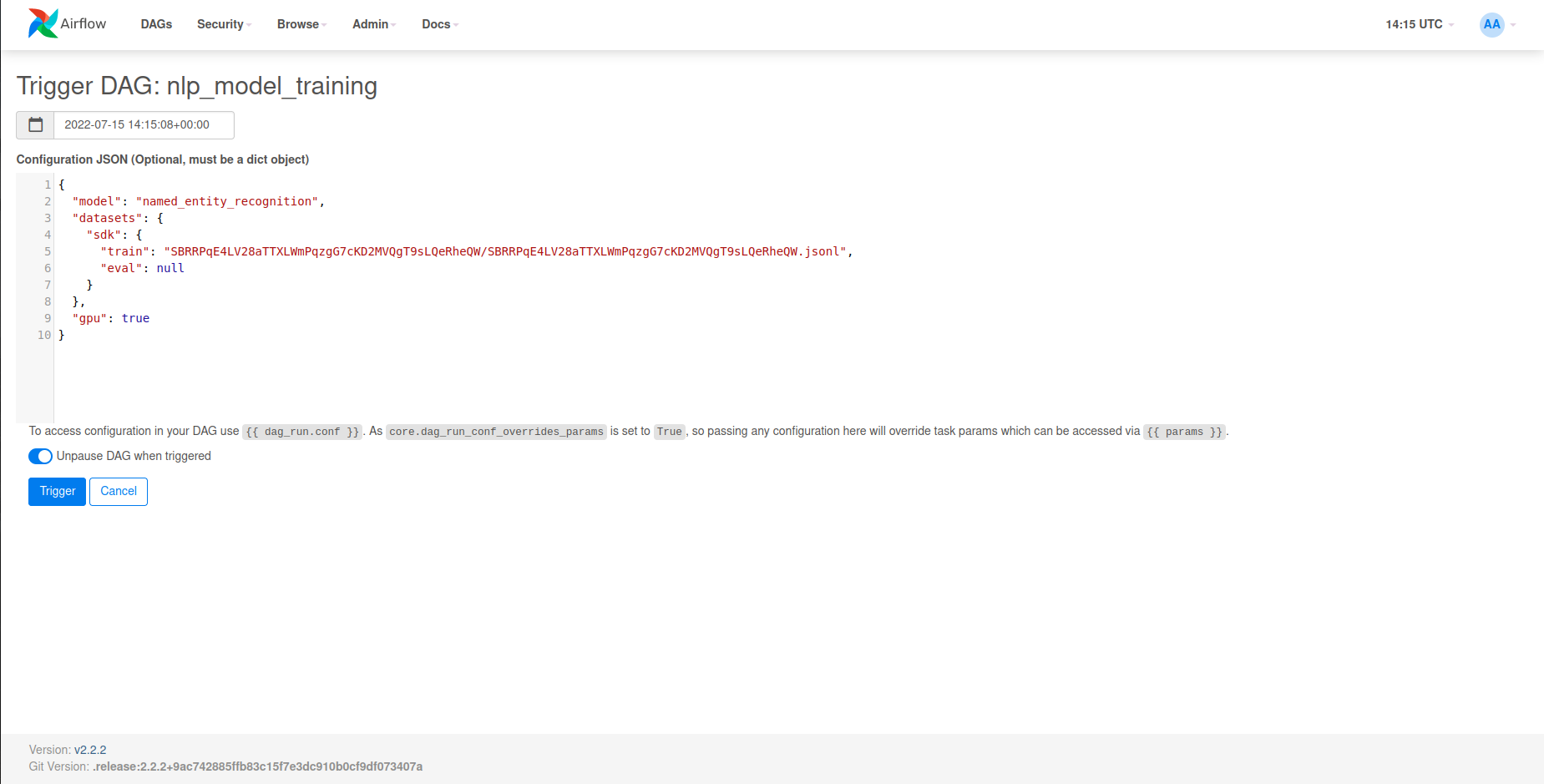
Within the Configuration JSON input box, you can input a request body in order to specify
how the training pipeline should run (see here for information about request bodies).
After inputting a request body, the Trigger button will trigger the DAG run.
After triggering the DAG you will be redirected towards the tree view of the DAG and you can monitor the progress and status of the current DAG run.
Uploading custom DAGs
If you have a custom DAG you wish to use in place of the NLP model training DAG, it may be uploaded via the GraphGrid CLI using the airflow upload command.
./bin/graphgrid airflow upload <path/to/custom/dag/file>
In order to ensure your custom DAG can be uploaded and run without error, it must be a single Python file without any local module dependencies.
Request Bodies / Configuration JSON
Request Bodies or Configuration JSON dictate the functioning of DAGs. For the NLP model training DAG this includes which model to train via the pipeline as well as the datasets and corpora.
{
"model": "named_entity_recognition",
"datasets": {
"sdk": {
"train": "SBRRPqE4LV28aTTXLWmPqzgG7cKD2MVQgT9sLQeRheQW/SBRRPqE4LV28aTTXLWmPqzgG7cKD2MVQgT9sLQeRheQW.jsonl",
"eval": null
}
},
"gpu": true
}
The fields are as follows:
model(string) - the name of the model to traindatasets(Map[String, Map[String, String]]) - the datasets/corpora to use for training and evaluationGPU(bool - optional, default:false) - whether to enable GPU passthrough and acceleration
GPU Limitations
Currently, only a handful of Linux distributions are supported with GPU acceleration via Airflow. Additionally, only one GPU accelerated training session can be run at once. However, multiple CPU-based training sessions can be run concurrently. These can also be mixed, e.g. 1 GPU accelerated training session with multiple CPU training sessions. Finally, not every GPU is currently supported for training, most GPUs released in and beyond 2020 are not compatible and supported for GPU acceleration. Use the GraphGrid CLI to check whether your environment is compatible.
GPU Concurrency
The nlp_model_training DAG has a branching path for training depending on whether
a GPU is being employed for the training session. In the case where a GPU is being used,
there is a basic subgraph responsible for job scheduling and management which
controls the concurrency of GPU training sessions.
The first important aspect of this management system is two new Airflow pools, which are
named gpu_preflight_pool and the gpu_pool. For context, every running task within a
DAGRun is placed within a pool. By default, tasks are placed within the default_pool which
is statically defined by Airflow and comes with 128 slots. Tasks can only run if they occupy
a slot within a pool. This means we can control task concurrency by placing specific tasks
into pools. Hence, the creation of the two aforementioned pools.
gpu_preflight_pool is statically defined and only has one slot. Every task
within the "GPU subgraph" besides train_model_gpu is placed within this pool.
This means that only one preflight task can be run at any one time across any training session.
This ensures that every heuristic check performed during the gpu_preflight_calcuation task
is accurate and not subject to any potential race conditions or unpredictable variability.
gpu_pool is a dynamically defined pool and changes based on gpu_preflight_configuration.
This allows the pool to increase in scenarios where gpu_preflight_configuration determined
that there is enough headroom for another concurrent GPU training session.
The next part of this system requires the introduction of the GraphGridTrainingRunningSensor, which
inherits from the BaseSensorOperator. Sensors are important and special types of operators
which detect when a specific condition occurs. For our purposes, this sensor detects
when all GPU training tasks are in a valid state (e.g. running or no state at all),
and all running tasks have healthy docker containers. For more information about sensors
refer to the airflow documentation here.
This is an important and necessary step since this allows us to block any further training
sessions and preflight calculations until we know all the training sessions are actually
running.
The GraphgridDockerOperator has a togglable GPU healthcheck which runs a query
to determine when a GPU training session has actually begun. The sensor makes
a basic docker request to get all the statuses of all the GPU training containers.
After the training sensor task succeeds, the task gpu_preflight_configuration begins.
This task performs multiple heuristics in order to get an accurate snapshot of the current
environment in terms of GPU usage. It uses this snapshot to determine whether another training session can
be run. In the case where it cannot, the process sleeps and then recursively calls the calculation
again. This task will continue to block/sleep and recursively call itself until we reach
the default maximum recursion depth in python of 1000. This gives an approximate
timeout of ~8-9 hours.
Assuming the gpu_preflight_configuration task succeeds, gpu_pool_setup is
then scheduled and run. gpu_pool_setup takes the pool size that the gpu_preflight_configuration
task returned and either creates the pool with that number of slots or modifies the existing
pool to match the newly calculated number of slots.
Finally, this subgraph/subDAG concludes with train_model_gpu which actually
trains the requested model within the dynamically changing gpu_pool.
Air traffic controller analogy
The role of the GPU subDAG is analogous to an air traffic controller. This concurrency system monitors all training sessions (Airplanes) and an environment's bandwidth for these training sessions (airport runway availability). Air traffic controllers attempt to schedule planes to land on runways while avoiding collisions and errors. This is exactly the same goal as this concurrency management system, as we want all training tasks (planes) to run without overexerting the local environment and crash.
The training sensor tells us where all planes currently are (i.e. the states of all the current training sessions). For planes, these states include "at the terminal", "approaching the runway", "on the runway", "taking off", "in the air". For our training tasks, they can be in states such as "queued", "running", "failed", "no state", etc. The training sensor queries the backend airflow database which gets us every state other than "in the air", this is due to the fact that while Airflow may state the task is "running", we do not know whether the GPU process and TensorFlow have actually begun and will be queryable for our heuristics calculations. This is where the docker healthcheck comes in, since that will only mark containers as healthy when they have actually started and are using a GPU. For instance there is a task queued for "take off" while another a task is "in the air" with a passing healthcheck. The concurrency system is doing its job to ensure that there are no "flight" delays. This means with these two queries we can get every state of the plane and accurately know when we should consider trying to land a plane or schedule another plane to take off.
The gpu_preflight_configuration is analogous to the air traffic controller checking
whether there are any available runways. This task looks at all the current
planes and can get a current snapshot of which runways are currently occupied by these planes
and which runways will be occupied in the future by other planes. Overall, the goal of this system is to "automagically" manage concurrency for GPU training
sessions in order to avoid all possible crashes. If we instead opted for a "hands off" approach
and let the planes and pilots decide for themselves where and when to land, then we would undoubtedly
have many crashes and/or inefficiencies where pilots are too conservative and inactive in terms
of deciding when to land or take off.