Data Replication with Fuze
Data replication is primarily used to handle load from data redundancy. If one database goes down, a second database can capture changes in the graph and then replicate those changes to the downed-database once it's brought up again. Fuze replication is bidirectional, so if you needed to bring either database down you could do so.
For instance, if you wanted to update to the latest version of ONgDB you could do so without any downtime. While database #1 is down, database #2 listens for new data and replicates what it captures to database #1.
Fuze replication is also capable of replicating targeted graph data between clusters. This would apply with GraphGrid deployment running in different geographical regions handling user data where some data has a boundary and cannot leave a region such as user data cannot leave the EU and therefore could not be replicated to the US but some of the data in the graph could be.
It's important to note that if replication has not been set up data already in your graph will not be replicated. Bidirectional replication should be used for planned downtime and replication of new or targeted data.
How to Set Up Bidirectional Data Replication
Replication uses ONgDB Writer and Trigger Policies to achieve bidirectional replication. Two ONgDB Writer policies need to be saved and activated. One listens
for txData from db-1 (database 1) and the other does the same for db-2 (database2). These policies also set the up the message broker endpoints that the txData
will be sent to. A Fuze Trigger Policy ensures that the triggers needed
for replication exist on both ONgDB instances.
For this tutorial, we'll set up bidirectional replication on two ONgDB instances and add TvSeries data to our graph for replication.
Steps to Set up Bidirectional Replication with Fuze:
Set up a second ONgDB instance.
Save and activate ONgDB Writer PolicyA.
Save and activate ONgDB Writer PolicyB.
Save and activate Fuze Replication Trigger Policy
Set Up A Second ONgDB Instance
The first step to bidirectional replication is to set up and launch a second ONgDB instance. Set up is done in the package's docker-compose.yml file.
The second ONgDB instance (ongdb2) will run on port 7575 and have a bolt server connection on port 7688. Navigate to the ongdb2 instance by going to
http://localhost:7474/browser/. This instance is connected to bolt://localhost:7688 (default username: ongdb default password: admin).
If you changed your login information from the default ONgDB values and are not sure what they are you can find them in the data/env directory in
the ongdb.env file.)
To set up the ongdb2 instance we need to edit the docker-compose.yml file in the project directory. To edit, run nano docker-compose.yml in your terminal. Once
in editing mode, carefully add the following under the ongdb definition already there:
Make sure that the formatting matches the other modules and services after pasting.
ongdb2:
image: 754290812573.dkr.ecr.us-west-2.amazonaws.com/ongdb-enterprise:1.0.0
ports:
- 7575:7575
- 7688:7688
ulimits:
nproc: 65535
nofile:
soft: 40000
hard: 40000
env_file:
- ${var.misc.graphgrid_data}/env/ongdb.env
- ${var.misc.graphgrid_data}/env/rabbitmq.env
environment:
- ONGDB_dbms_connector_http_listen__address=0.0.0.0:7575
- ONGDB_dbms_connector_bolt_listen__address=0.0.0.0:7688
- ONGDB_dbms_memory_heap_initial__size=1024m
- ONGDB_dbms_memory_heap_max__size=1024m
- ONGDB_dbms_memory_pagecache_size=1024m
- ONGDB_dbms_security_procedures_unrestricted=apoc.*
- ONGDB_dbms_security_allow__csv__import__from__file__urls=true
- ONGDB_apoc_import_file_enabled=true
- ONGDB_apoc_import_file_use__ongdb__config=true
- ONGDB_apoc_trigger_enabled=true
- ONGDB_apoc_jobs_default_num_threads=4
- ONGDB_apoc_jobs_scheduled_num_threads=4
- ONGDB_dbms_logs_query_enabled=true
- ONGDB_dbms_logs_query_parameter__logging__enabled=true
- ONGDB_dbms_logs_query_threshold=20ms
# RabbitMQ apoc integration
- ONGDB_apoc_broker_rabbitmq_type=RABBITMQ
- ONGDB_apoc_broker_rabbitmq_enabled=true
- ONGDB_apoc_broker_rabbitmq_host=rabbitmq
- ONGDB_apoc_broker_rabbitmq_port=5672
- ONGDB_apoc_broker_rabbitmq_vhost=/
# Apoc broker logging
- ONGDB_apoc_brokers_logs_enabled=true
- ONGDB_apoc_brokers_logs_dirPath=logs/
volumes:
- ${var.misc.graphgrid_data}/ongdb/data2:/data
- ${var.misc.graphgrid_data}/ongdb/logs2:/logs
- ${var.misc.graphgrid_data}/ongdb/import:/import
- ${var.misc.graphgrid_data}/ongdb/plugins:/plugins
depends_on:
- elasticsearch
logging:
driver: json-file
options:
max-size: 10m
max-file: '6'
Once this is added be sure to start ongdb2:
./bin/graphgrid start ongdb2
ONgDB Writer Policies
The next step is to save and activate two ONgDB Writer policies for each database. We'll refer to them as ONgDB Writer Policy A and ONgDB Writer Policy B.
ONgDB Writer policies define the settings to use when executing a TransactionRequest and/or a list of message broker endpoints that listen for TransactionRequests to execute. A ONgDB Writer policy has the following elements:
- metadata - Information to uniquely identify the policy.
- defaultNeo4jCredentials - The Neo4jCredentials to use if a request does not specify any.
- listeningBrokerEndpoints - A list of broker endpoints on which to listen for requests.
- maxReadAttempts - The maximum number of times to attempt executing the statements in a read request before quarantining the request.
- maxWriteAttempts - The maximum number of times to attempt executing a write request before quarantining the request.
- minBatchSize - the minimum number of TransactionStatements that must be gathered into a batch request before executing.
- maxBatchSize - (currently unavailable) the maximum number of TransactionStatements that may be present in a batch request.
If you are using the default ONgDB username and password you can use these request bodies as they are. If not, be sure to update your credentials accordingly inside the request body.
To set up bidirectional replication, the ONgDB Writer policies need to listen for txData messages on RabbitMQ and write any changes to ONgDB. txData is a
structure generated by internal apoc trigger code that captures changes produced by write transactions (often from Geequel queries) in a json format.
ONgDB Writer Policy A
This is the ONgDB Writer policy for db-1.
curl --location --request POST "${API_BASE}/1.0/fuze/default/savePolicy/fuze-replication-ongdbWriter-policyA" \
--header "Authorization: Bearer ${BEARER_TOKEN}" \
--header 'Content-Type: application/json' \
--data-raw '{
"metadata": {
"displayName": "ongdbWriter-policyA",
"description": "Listen for TxData messages on RMQ and write to ongdb"
},
"status": "ACTIVE",
"defaultNeo4jCredentials": {
"uri": "bolt://ongdb:7687",
"username": "ongdb",
"password": "admin"
},
"txDataBrokerEndpoints": [
{
"broker": "RABBITMQ",
"exchange": "com.graphgrid.fuze.exchange.A",
"routingKey": "com.graphgrid.fuze.key.A",
"queue": "com.graphgrid.fuze.queue.A"
}
]
}'
ONgDB Writer Policy B
This is the ONgDB Writer policy for db-2.
curl --location --request POST "${API_BASE}/1.0/fuze/default/savePolicy/fuze-replication-ongdbWriter-policyB" \
--header "Authorization: Bearer ${BEARER_TOKEN}" \
--header 'Content-Type: application/json' \
--data-raw '{
"metadata": {
"displayName": "ongdbWriter-policyB",
"description": "Listen for TxData messages on RMQ and write to ongdb2"
},
"status": "ACTIVE",
"defaultNeo4jCredentials": {
"uri": "bolt://ongdb2:7688",
"username": "ongdb",
"password": "admin"
},
"txDataBrokerEndpoints": [
{
"broker": "RABBITMQ",
"exchange": "com.graphgrid.fuze.exchange.B",
"routingKey": "com.graphgrid.fuze.key.B",
"queue": "com.graphgrid.fuze.queue.B"
}
],
"lastTransactionId": 1
}'
Save and Activate Fuze Replication Trigger Policy
The Trigger policy will ensure that the triggers needed for replication exist on both ONgDB instances.
There are a couple of different properties that are important to note in the Trigger Policy, uidKeys and uidLabels.
uidKeys are used to define the globally unique identifier that the txData should use to refer to the nodes (default is the node/rel (entity) id key, but we often
set it to be the grn). ONgDB by default assigns each node/relationship a unique identifier (ex. id: 12345). However, if that node/relationsip is deleted the id
is reused. To get around this we set the uidKey to use the grn which is globally unique.
uidLabels are a similar idea where they are used to provide the best label to identify the node/relationship with. By default the trigger takes the first label
in the node/relationship labels list.
For our Trigger Policy we'll set the uidKeys to use the grn of each node/relationship. The uidLabels will be Movie, Person, and our new data TvSeries.
curl --location --request POST "${API_BASE}/1.0/fuze/default/savePolicy/fuze-replication-trigger-policy" \
--header "Authorization: Bearer ${BEARER_TOKEN}" \
--header 'Content-Type: application/json' \
--data-raw '{
"metadata": {
"description": "ensure that the triggers needed for replication exist on both ongdb instances",
"displayName": "fuze-replication-triggerPolicy"
},
"status": "ACTIVE",
"instances": {
"ongdb1": {
"uri": "bolt://ongdb:7687",
"username": "ongdb",
"password": "admin"
},
"ongdb2": {
"uri": "bolt://ongdb2:7688",
"username": "ongdb",
"password": "admin"
}
},
"triggers": [
{
"triggerName": "replicationTxDataTrigger",
"triggerCypher": "CALL apoc.broker.send(\"rabbitmq\", {txData: {txData}, lastTxId: {lastTxId}, sendingUri: \"bolt://ongdb:7687\"}, {queueName: \"com.graphgrid.fuze.queue.B\", exchangeName: \"com.graphgrid.fuze.exchange.B\", routingKey: \"com.graphgrid.fuze.key.B\"}) YIELD connectionName, message, configuration RETURN 1",
"phase": "after",
"uidKeys": [
"grn"
],
"uidLabels": [
"Person",
"Movie",
"TvSeries"
],
"includedInstances": [
"ongdb1"
]
},
{
"triggerName": "replicationTxDataTrigger",
"triggerCypher": "CALL apoc.broker.send(\"rabbitmq\", {txData: {txData}, lastTxId: {lastTxId}, sendingUri: \"bolt://ongdb2:7688\"}, {queueName: \"com.graphgrid.fuze.queue.A\", exchangeName: \"com.graphgrid.fuze.exchange.A\", routingKey: \"com.graphgrid.fuze.key.A\"}) YIELD connectionName, message, configuration RETURN 1",
"phase": "after",
"uidKeys": [
"grn"
],
"uidLabels": [
"Person",
"Movie",
"TvSeries"
],
"excludedInstances": [
"ongdb1"
]
},
{
"triggerName": "replicationAddGrnToCreatedNodes",
"triggerCypher": "UNWIND {createdNodes} AS n WITH n WHERE NOT EXISTS (n.grn) CALL apoc.do.when( size(labels(n)) > 1, \"SET n.grn = '\''grn:gg:'\'' + lower(filter(l IN labels(n)WHERE l <> '\''Resource'\'')[0]) + '\'':'\'' + apoc.text.random(44)\" , \"SET n.grn = '\''grn:gg:'\'' + toLower(labels(n)[0]) + '\'':'\'' + apoc.text.random(44)\", {n : n } ) yield value RETURN n",
"phase": "before",
"includedInstances": [
"ongdb2"
]
},
{
"triggerName": "replicationAddGrnToCreatedRelationships",
"triggerCypher": "UNWIND {createdRelationships} AS r WITH r WHERE NOT exists(r.grn) SET r.grn = '\''grn:gg:'\'' + toLower(type(r)) + '\'':'\'' + apoc.text.random(44)",
"phase": "before",
"includedInstances": [
"ongdb2"
]
}
]
}'
Policy JSON
{
"metadata": {
"description": "ensure that the triggers needed for replication exist on both ongdb instances",
"displayName": "fuze-replication-triggerPolicy"
},
"status": "ACTIVE",
"instances": {
"ongdb1": {
"uri": "bolt://ongdb:7687",
"username": "ongdb",
"password": "admin"
},
"ongdb2": {
"uri": "bolt://ongdb2:7688",
"username": "ongdb",
"password": "admin"
}
},
"triggers": [
{
"triggerName": "replicationTxDataTrigger",
"triggerCypher": "CALL apoc.broker.send(\"rabbitmq\", {txData: {txData}, lastTxId: {lastTxId}, sendingUri: \"bolt://ongdb:7687\"}, {queueName: \"com.graphgrid.fuze.queue.B\", exchangeName: \"com.graphgrid.fuze.exchange.B\", routingKey: \"com.graphgrid.fuze.key.B\"}) YIELD connectionName, message, configuration RETURN 1",
"phase": "after",
"uidKeys": [
"grn"
],
"uidLabels": [
"Person",
"Movie",
"TvSeries"
],
"includedInstances": [
"ongdb1"
]
},
{
"triggerName": "replicationTxDataTrigger",
"triggerCypher": "CALL apoc.broker.send(\"rabbitmq\", {txData: {txData}, lastTxId: {lastTxId}, sendingUri: \"bolt://ongdb2:7688\"}, {queueName: \"com.graphgrid.fuze.queue.A\", exchangeName: \"com.graphgrid.fuze.exchange.A\", routingKey: \"com.graphgrid.fuze.key.A\"}) YIELD connectionName, message, configuration RETURN 1",
"phase": "after",
"uidKeys": [
"grn"
],
"uidLabels": [
"Person",
"Movie",
"TvSeries"
],
"excludedInstances": [
"ongdb1"
]
},
{
"triggerName": "replicationAddGrnToCreatedNodes",
"triggerCypher": "UNWIND {createdNodes} AS n WITH n WHERE NOT EXISTS (n.grn) CALL apoc.do.when( size(labels(n)) > 1, \"SET n.grn = 'grn:gg:' + lower(filter(l IN labels(n)WHERE l <> 'Resource')[0]) + ':' + apoc.text.random(44)\" , \"SET n.grn = 'grn:gg:' + toLower(labels(n)[0]) + ':' + apoc.text.random(44)\", {n : n } ) yield value RETURN n",
"phase": "before",
"includedInstances": [
"ongdb2"
]
},
{
"triggerName": "replicationAddGrnToCreatedRelationships",
"triggerCypher": "UNWIND {createdRelationships} AS r WITH r WHERE NOT exists(r.grn) SET r.grn = 'grn:gg:' + toLower(type(r)) + ':' + apoc.text.random(44)",
"phase": "before",
"includedInstances": [
"ongdb2"
]
}
]
}
Viewing Both Databases
After setting up and activating the trigger policy we can ensure that the bidirectional replication process worked.
Head to your db-1 instance at http://localhost:7474/browser/ and connect to the ONgDB server using the bolt://loclhost:7687 connection. To view db-2, in a
separate window or tab, head to http://localhost:7575/browser/. Once in the db-2 browser you will connect to bolt://localhost:7688 using your ONgDB credentials
(default username: ongdb default password: admin).
To ensure that replication is properly set up you can run this Geequel query in both databases:
CALL apoc.trigger.list
This query should return a list of triggers including these three:
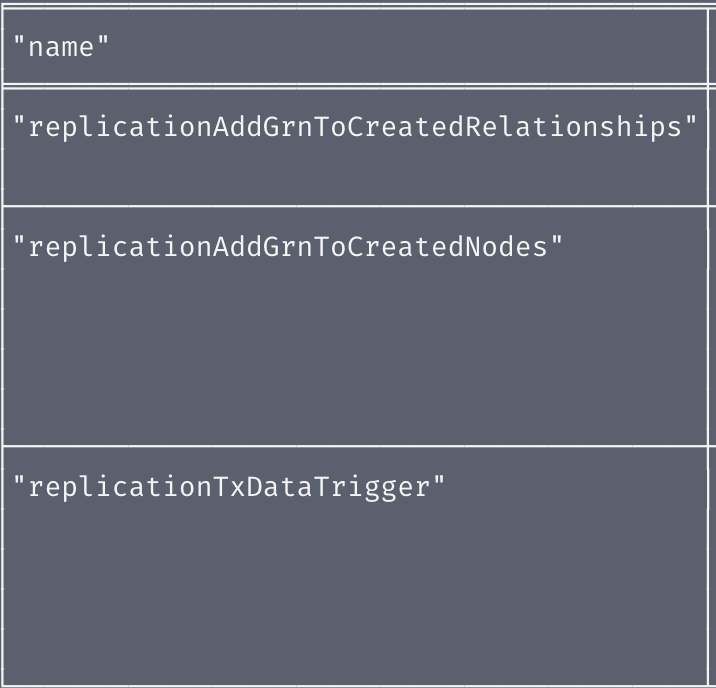
After you've confirmed that the three triggers needed for replication have been set we can add some new data to see them in action! Add this TV series data to one of the graph databases (remember Fuze
replication is bidirectional!). Query all nodes with node label TvSeries (MATCH (n:TvSeries) RETURN n) you should see that the TvSeries data exists on both graphs!
![Screenshot]](/img/screenshots/db1-db2-replication.png)
Feel free to play around with what data you can replicate to get the feel for bidirectional replication. This tutorial set the Fuze Trigger Policy to listen for
Movie and Person nodes as well! Try creating some new data and adding it to the opposite graph that you added the TvSeries data to.
CREATE (WorldsEnd:Movie {title:"World's End", released:2013, tagline:'Twelve Pubs. Total Annihilation. Now theyre going home, but it feels like another planet. Drink responsibly.'})